SMFS: making agentic retrieval 55% cheaper AND more accurate


We launched SMFS.ai (Supermemory Filesystem) a few weeks ago, with a simple bet: We can redesign the filesystem specifically for agents, with special files, structures, and commands that it can use for it's tasks. Today, SMFS is used by hundreds of companies to power their agents.
TLDR: You can read the report here - https://smfs.ai/research/memory-as-a-filesystem/
If you missed that launch, here's a quick summary of SMFS:
- Agentic Filesystem powered by FUSE that loads instantly.
- /profile.md auto-generated and updated based on content in the filesystem.
- Multi-modal data (images, etc) can be grepped through, as SMFS runs OCR stores them as text files
- Grep and some other commands are replaced to give the agent an option to do semantic search as well.
All of that, built into a true filesystem - that the agent can use and navigate.
It was time for us to run some benchmarks!
In this blog, I'll go over some of the intuition and introduce the things we did to fix them.
The problems
Two halves, each broken on its own.
Agentic search is what every coding agent already does: list a directory, cat a few files, grep for a string, reason, repeat. It's powerful because the agent stays in control. It's kinda like having a stack of books in front of you - without a title. In order to find a specific thing, you'll have to open the books, remember which had what, and then skim through each page to get something, holding all that traversal in your "context window"
Semantic retrieval, RAG-style, SHOULD fix exactly that. One query pulls content by meaning, surfacing passages no grep could locate. But it hands back a top-K list of chunks ripped out of context: excerpts with no neighbors, no surrounding file, no thread to pull. The agent gets an answer fragment and nowhere to stand. Multi-hop reasoning suffers worst, because the next question depends on context the chunk threw away.
Our users were always stuck choosing. Agentic search gives structure and control but can't find things at scale. File search finds things but severs them from the structure the agent needs to reason. Pick one and you've picked your failure mode.
The whole point is: you shouldn't have to pick.
The bottleneck of agent memory was never the speed of a single retrieval. It's the number of retrievals an agent issues before it has enough context to answer - every one of them inflating the context window with paths, partial reads, and overlapping chunks until reasoning degrades.
Agentic search inflates that count by exploring blindly. File search inflates it by making the agent re-search for the context each chunk is missing.
Combine them and the count collapses. Semantic search lands on a path. The agent reads the surrounding file, follows the thread, greps the subtree, agentically, from a starting point it actually trusts. You get the reach of file search and the control of agentic search in the same motion. That's the bet. That's the north star.
Introducing xAFS
To measure and test the quality of SMFS, we needed a realistic benchmark with:
- Both conversational and document data (Memory + Filesystem)
- Gradually increasing number of files (So we can determine the curve of change)
- Non-Needle-in-haystack questions that test for multi-hop, temporal and other types of queries
- Each file being more than 10k tokens
- Testing upto 10k Files, all of them being one coherent "Story" with coherent facts
There was no benchmark for agentic search specifically on the internet - so, we created one.
This benchmark is specifically made for agentic retrieval, and extendable for any use cases! We invite people to come and try it out https://huggingface.co/datasets/supermemory/xAFS
How SMFS performed
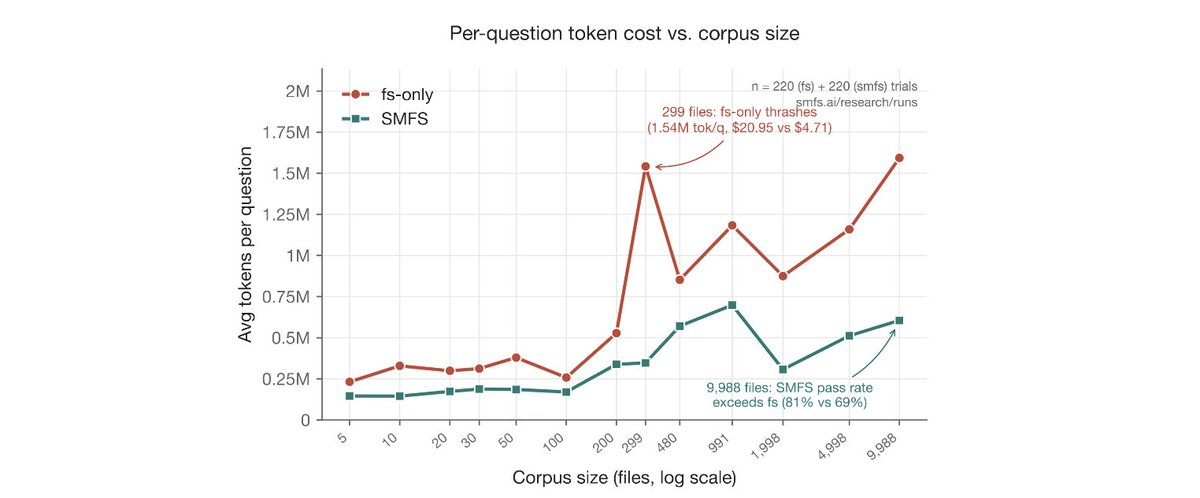
SMFS results were truly staggering. At 10,000 files, the standard filesystem agent's accuracy collapses to 69%. Ours holds at 81%.
Total bill across the whole eval: $2,103 vs $946. 55% cheaper.
On one corpus the baseline thrashed to $20.95 per question. Ours answered the same question for $4.71.
53.8% fewer tokens. 53.1% fewer tokens per _correct_ answer.
Claude's harness used −66% tokens, and −60% tool calls — and it got more accurate.All the evaluation runs are publicly available at smfs.ai/research/runs/, where each run can be inspected. Here's a run where smfs used 50% less tokens, latency and cost:

Work doesn't end here
We have published a detailed report about SMFS - How it has a sync engine, Profiles, using Grep as retrieval, and all the other thought we put in, in a technical report here - https://smfs.ai/research/memory-as-a-filesystem/
