Dear reader, we just made supermemory insanely cheap... the Context Cloud

When I first started building supermemory, I had one goal: To build the best memory system for AI. I would talk to customers, and find out that memory was not the only thing they needed - They were all setting up 7-8 different vendors at the same time.
Memory, Retrieval, Profiles, reranking, embedding, etc.
We had all of those features before already, but our positioning made it unclear what we offer, and led to people either being confused or paying too much for what they want to do.
The product kept changing and evolving, and we started doing more and more things with the product.
Today, Supermemory can:
- Parse and extract any modality of content (PDFs, images, etc.)
- Learn in real time about entities and create a growing graph about them (SOTA Memory)
- Large scale RAG (with a bunch of features in it)
(And RAG+Memory available as a filesystem smfs.ai) - Creating profiles of your users for short-term understanding (User Profiles)
- Figuring out what your users are doing / understanding patterns and use cases (Qualitative Observability)
- Keep external services like Google Drive, Notion, S3, Crawled websites, etc. in sync in real-time (Sync)
- ... and more.
All of these have been natural progressions of how we think agents will be built - with lego blocks, or composition of multiple such layers, using them in the best way possible to get things done.
Each use case of memory is slightly different, and has different tradeoffs. A healthcare assistant needs to remember things about health, but also needs best quality retrieval, with a latency tradeoff being acceptable. Similarly, a research/coding assistant using subagents might be OK to load things into context in the explore phase.
To serve all of these use cases, we started opening up our API and stopped being opinionated. So now, supermemory is truly yours. It's your legos to build whatever you can wish.
Me and the team sat together to find what can _not_ be built with supermemory, and honestly, we could not come up with any good answer.
Why we did not change the pricing before
The only thing stopping us from going all into this non-opinionated legos-for-context-infrastructure was the fact that our pricing only had two metrics attached to it: `tokens ingested` and `search queries`
Well, in reality it was just one metric (tokens) as we knew no one would hit our extremely high limit of search queries, ever.
So, we started deciding the new pricing: It had to be composable yet easy - Unit-based but not credits, as we don't want people to worry about credits and wonder how our pricing works (We wanted to give our users full transparency)
In our new pricing, we figured it out - All usage draws from the same credit pool, and is very clear on what is offered.
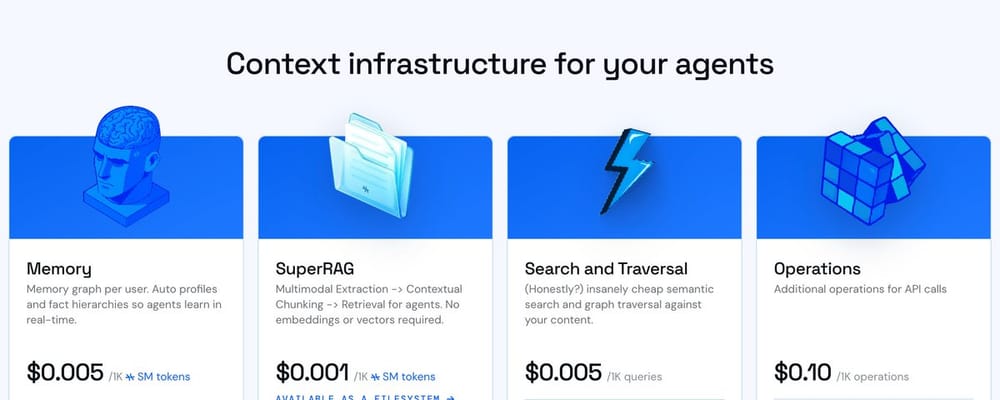
- Rich tokens / normal tokens - Multi-modal content will be billed 2x normal token count
- Separate pricing for retrieval (Which also makes it the cheapest managed retrieval service!)
- Charging for operations - For all the little configuration that you can do with supermemory, they are now counted as operations.
- Supermemory tokens - Unlike LLM tokens, we only count and bill on the unique tokens we've seen. Which means if it's an ongoing converastion with an LLM, we will literally only bill on the unique tokens in the entire conversation. Often times this is 5-10x less than text tokens themselves.
Depending on how you count it, this makes Supermemory the cheapest memory layer on the market. yes, headline prices didn't move. The math underneath did. Most of you will pay less for the same workload starting next month, and some of you will pay significantly less.
And now, no matter what, our customers have the perfect breakdown of how much they spend.
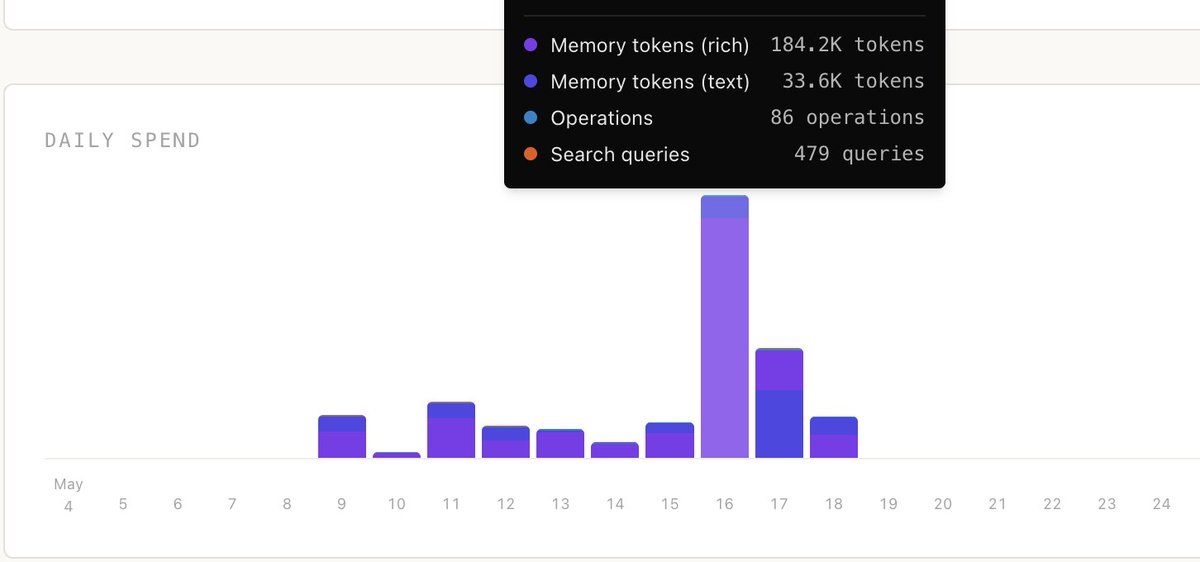
This, along with the launch of our filesystem (smfs.ai) marks the transition of supermemory moving from just a memory system to becoming the Context Cloud.
The legos to build your agents, the way they should be. And we provide the best, most reliable, and delightful infrastructure components that doesn't break your bank while helps you build and ship fast.
We're ready for the next chapter. are you?