
Mem0 vs supermemory: Why Scira AI Switched And What's Better For You?

“Mem0 was not great. Glad to have found supermemory”
That’s how Zaid Mukaddam, founder of Scira AI, summed up his team’s first attempt at adding memory to their product. Latency was unbearable, indexing was unreliable, and it simply didn’t scale.
Scira is an open-source Perplexity alternative, built for people who want more than quick answers. Its users run parallel queries, build structured research plans, and increasingly, want memory: the ability to pull in their own notes, past searches, or connect data from sources like Notion and Google Docs.
When Scira tried to deliver that with Mem0, the experience fell apart, and they had to decide between patching around a broken system or finding something better.
They chose Supermemory. If you’re also confused between Mem0 and Supermemory for your product, this article will walk you through Scira’s story and then dive into the technical differences that matter while making this choice.
Slow, Unstable, Unscalable
Scira’s users weren’t just looking things up once and moving on. They wanted a way to carry context forward. A researcher might run a set of queries today, then come back tomorrow and ask: “What was that thing I found last time? Bring it into this conversation so I can continue.”
Others wanted to import their own notes or documents so the model could reference them directly. Many asked for connectors to sources like Notion, Google Docs, tweets, and PDFs.
When Scira tried to power all this with Mem0, the experience quickly broke down:
- Latency was “super bad.” Imports dragged and slowed the research flow.
- Indexing was unreliable. Zaid: “Every time it was indexing something, it wouldn’t add it to the memories.”
- Context recall failed. Users trying to bring past results into a new query often saw nothing come back.
- Scaling was weak. As more users added data, performance degraded.
- Connectors weren’t usable. The integrations people wanted most just weren’t there.
Instead of making research smoother, Mem0 made memory the weakest part of the product.
Making The Switch
Once Zaid had had enough, he pushed for migration, and the team tried Supermemory. The difference showed up immediately.
Integration was straightforward. Zaid described the APIs as stable and simple to work with. A few bugs cropped up during testing, but they were fixed pretty quickly.
- Setup was fast. APIs were “pretty straightforward.” Testing was quick, and migration didn’t drag out.
- Stability improved overnight. Supermemory consistently stored and recalled entries, solving the indexing failures that plagued Mem0.
- Latency dropped. Scira went from a heavy app to one that ran cleanly even with memory features enabled.
- Connectors worked out of the box. Sources like Notion, Google Docs, and tweets could finally be brought into search.
- Support was responsive. Zaid: “I had some issues; they were fixed very quickly.”
Or as he put it more bluntly: “A thousand times better than Mem0.”
Results and Growth
The impact of switching to Supermemory was clear.
- Usage grew by ~32%. After the memory feature went live, adoption went up.
- 10 customers signed up because of memory. These were pro-researchers who cared about context.
- Users gave better feedback. Memory went from a weak point to something people valued.
Performance improved. The app felt lighter, latency dropped, and recall was reliable at scale.
Mem0 vs Supermemory: Technical Comparison
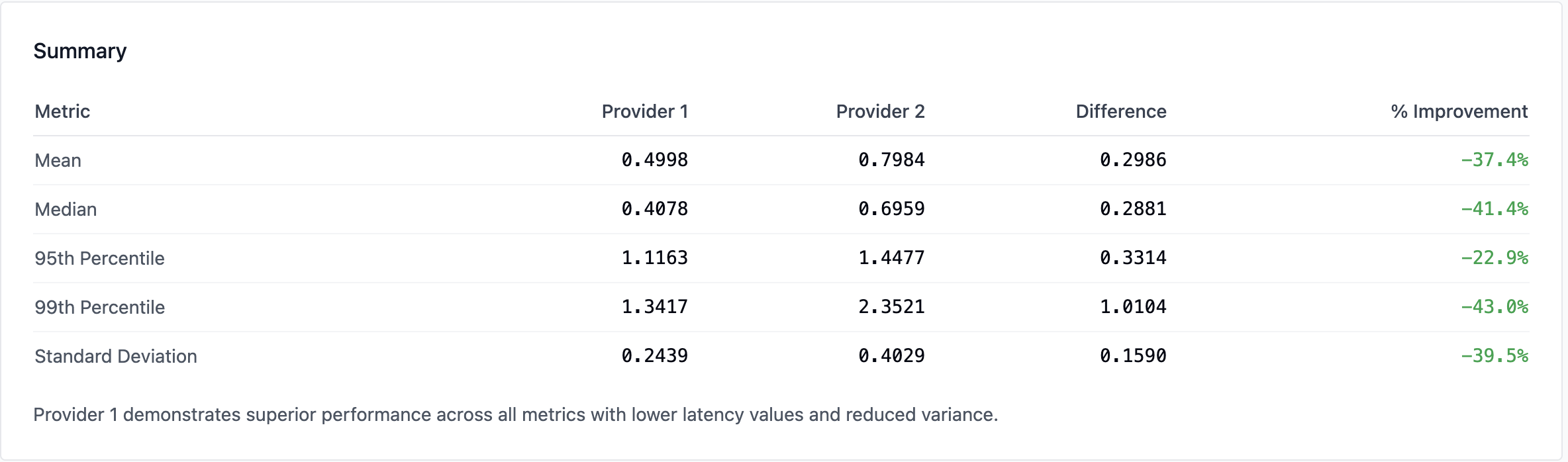
Here are some reproducible comparison of both quality and latency for Supermemory vs Mem0
Latency comparisons at scale, at n=602
Dataset used: LoCoMo
Provider 1: supermemory
Provider 2: mem0
Mean Improvement: 37.4%
Median Improvement: 41.4%
P95 Improvement: 22.9%
P99 Improvement: 43.0%
Stability Gain: 39.5%
Max Value: 60%
Quality comparison
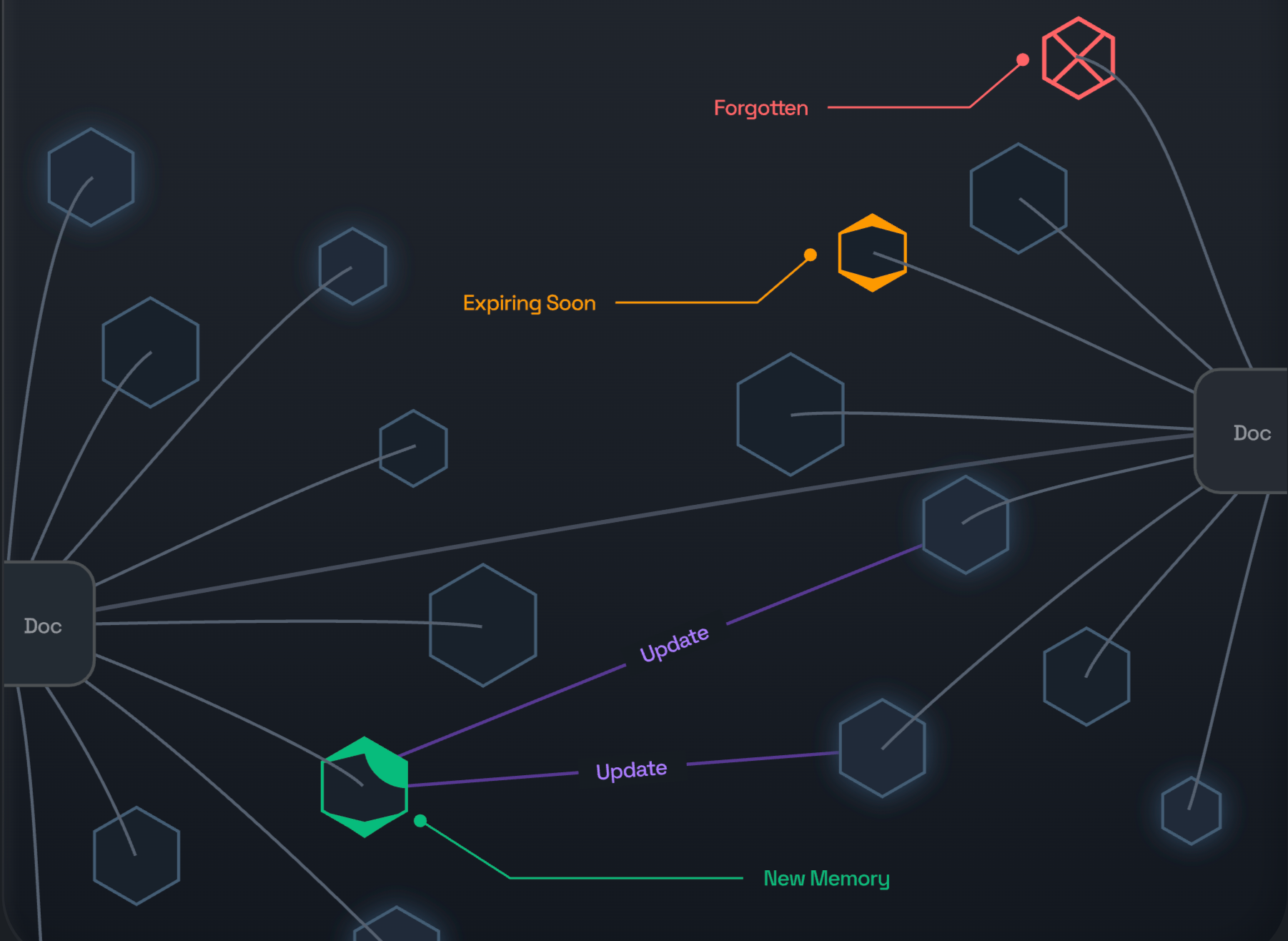
Fundamentally, instead of relying on a flat structure, supermemory built ground up on these principles:
- Forgetfulness
- Versioned memories
- Inferred (Derived) memories
- Chaining, grouping and growing
We will be publishing research and empirical results about this soon!
However, mem0 is a store. You get CRUD operations and filters. You can save an entity, scope it to a user, and query it back. That’s useful, but it’s table stakes. Nothing in Mem0 goes beyond the mechanics of persistence and retrieval.
That’s why developers run into walls with it: as soon as you need ingestion pipelines, connectors, or intelligent recall, you’re left building them yourself.
On the other hand, Supermemory is a memory engine. We designed it to behave like our brain, not a database. That means:
- Ingestion and connectors are built in. Data like documents, images, PDFs, videos, etc., come in from Google Drive, Notion, OneDrive, and more automatically. You don’t have to build your own sync layer; we ship it, and we document the sync cycles down to the minute.
- We analyze and infer relationships. Every item ingested is embedded, but also structured into a graph. Relationships are mapped across entities, so you don’t get just “similar text.” You’ll get actually intelligent inferences like you would expect from the human brain.
- Intelligent retrieval logic. Query rewriting, reranking, and filtering are part of the stack. If your user asks something fuzzy, Supermemory still finds the relevant item. With Mem0, you’d be writing this logic yourself on top of raw vectors.
- Forgetfulness and inferences: Forgetting random, unnecessary things is a feature. Supermemory auto-forgets things that are not important after a certain time. If a user was looking for the best laundry detergent to use, it’s not something the AI should remember forever.
- Memory Router. Storage is just the start. Supermemory extends into application-level products. Memory Routergives your users an effectively unlimited context window for their conversations. That’s memory at the UX layer, not just at the infra layer.
- Scale without collapse. We designed for high-volume ingestion (100K+ token docs, multimodal data). Latency targets are sub-400ms, even under load. This isn’t “fine in a benchmark, bad in production.” It’s been battle-tested in real apps like Flow, Montra, Cluely, Rube and more.
This is why we say Supermemory adds actual memory to your product. It’s not about CRUD. It’s about a system that ingests, analyzes, links, and infers the same way your brain does when it remembers.
So the choice is straightforward:
- If you want a database API with “memory” branding, Mem0 will give you CRUD.
- If you want your product to think back, recall, and anticipate, you need a memory engine. That’s what Supermemory is.