supermemory will make your Hermes-agent crazy powerful


Today, we are launching supermemory support to your Hermes agent
TLDR: you can use supermemory now in your Hermes agent, it totally free to get started - https://supermemory.ai/docs/integrations/hermes
In case you missed it: Hermes Agent is a self-improving AI agent from Nous Research. It meets you where you already work—Telegram, Discord, Slack, WhatsApp, Signal, and the CLI from a single gateway, with everything from voice-memo transcription to scheduled automations.
We on the Supermemory team started using Hermes a few weeks ago. It really does work great out of the box, and it’s easy to set up. One thing we kept hitting, though: the agent doesn’t reliably know who we are, what we’re working on, and we need a way to keep memory scoped so it doesn’t bleed across contexts.
You might say: Hermes already has built-in memory. True—and it’s good. But what people expect from “memory” is growing past a single flat file**.** Built-in MEMORY.md and USER.md are a solid baseline; they’re not always enough when you want structure and isolation.
For example:
- “I don’t want work context surfacing when I’m chatting about personal stuff.”
- “I want knowledge organized per project, not one giant mix in one file.”
…and plenty of cases like that.
At Supermemory, we build memory infrastructure for AI agents and already power memory for tens of thousands of AI applications. We asked ourselves: what’s the best way to give Hermes a memory layer that actually fits those real-world constraints?
So we’re introducing…
Today, we are launching supermemory support to your Hermes agent
TLDR: you can use supermemory now in your Hermes agent, it totally free to get started - https://hermes-agent.nousresearch.com/docs/user-guide/features/memory-providers#supermemory
In case you missed it: Hermes Agent is a self-improving AI agent from Nous Research. It meets you where you already work—Telegram, Discord, Slack, WhatsApp, Signal, and the CLI from a single gateway, with everything from voice-memo transcription to scheduled automations.
We on the Supermemory team started using Hermes a few weeks ago. It really does work great out of the box, and it’s easy to set up. One thing we kept hitting, though: the agent doesn’t reliably know who we are, what we’re working on, and we need a way to keep memory scoped so it doesn’t bleed across contexts.
You might say: Hermes already has built-in memory. True—and it’s good. But what people expect from “memory” is growing past a single flat file**.** Built-in MEMORY.md and USER.md are a solid baseline; they’re not always enough when you want structure and isolation.
For example:
- “I don’t want work context surfacing when I’m chatting about personal stuff.”
- “I want knowledge organized per project, not one giant mix in one file.”
…and plenty of cases like that.
At Supermemory, we build memory infrastructure for AI agents and already power memory for tens of thousands of AI applications. We asked ourselves: what’s the best way to give Hermes a memory layer that actually fits those real-world constraints?
So we’re introducing…

Supermemory plugin for Hermes Agent
The integration is a native memory provider in Hermes: it plugs into the same lifecycle hooks the core agent already uses—not a bolt-on script you hope the model remembers to run. You get profiles, search, automatic capture of turns, optional multi-container routing for separate namespaces, and guardrails when the API is unhappy.
Here’s what that actually looks like in practice.
It grows. it forgets. it changes. it understands time. It is native.
We believe the important core concepts of memory are: Knowledge updates, Temporal and multi-session reasoning, as well as forgetfulness(!). Because this infrastructure is built on top of our knowledge graph, graph memory automatically handles these things. https://supermemory.ai/docs/concepts/graph-memory
Instead of the agent choosing to remember stuff, supermemory selectively remembers things that may be very important for the user, but it always indexes everything! The reason why we index everything is because memory is inherently lossy and you can never predict what the assistant will need on answering time. If we have a memory, it’s provided to the agent. Otherwise, the raw chunk is sent, and memories are derived out of it in the future.
Additionally, the engine also forgets things that may not be important in the future.
it knows who you are (and what you’re in the middle of)
Supermemory maintains an evolving user profile → static facts and dynamic context. The Hermes provider refreshes that material and can surface it in the system prompt, so when you open a new session you’re not re-introducing yourself from zero.
This means that even when you say “Hi”, it already knows your name, and everything. No prompting, no needle-in-haystack.
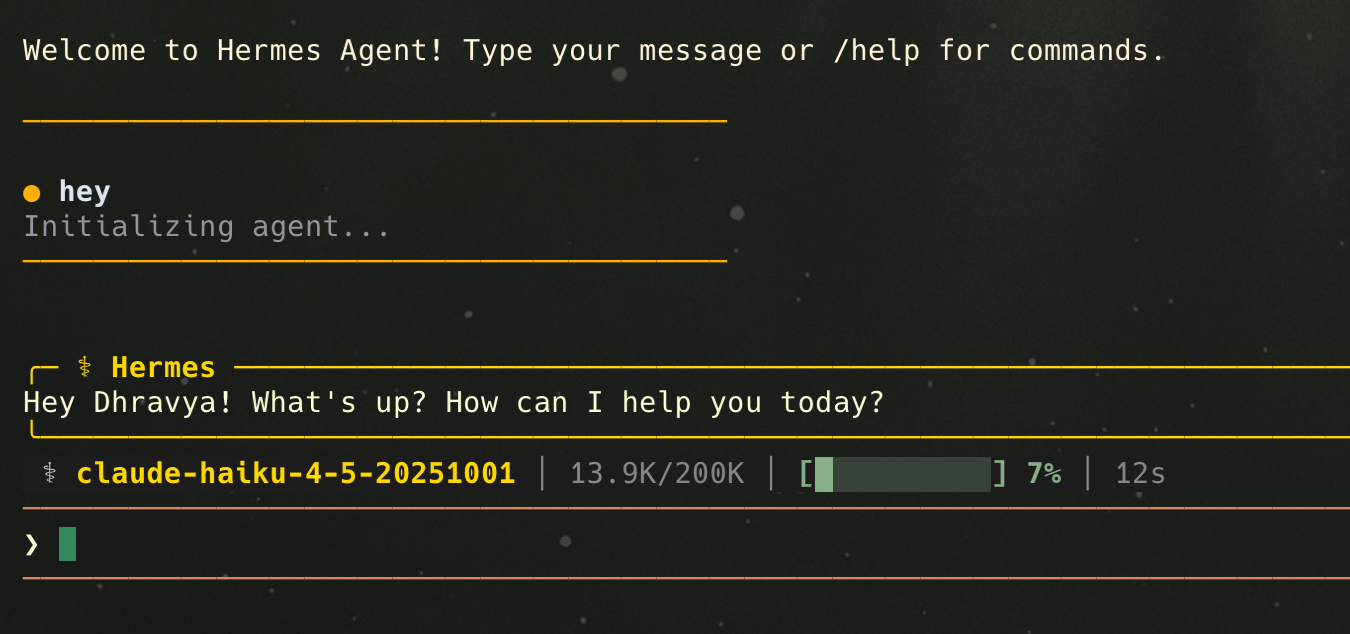
it stays scoped when you need it to
Hermes profiles already separate config and home directories. The plugin aligns with that: by default your primary Supermemory container tag is scoped like hermes-{profile}, so different Hermes profiles don’t stomp each other.
If you want to go further work vs personal, project-shaped buckets you can enable multi-container routing: you declare extra container tags and short descriptions in config; the model can pass an optional container_tag on the Supermemory tools for those namespaces.
Here is an example, where supermemory auto switching the container tags
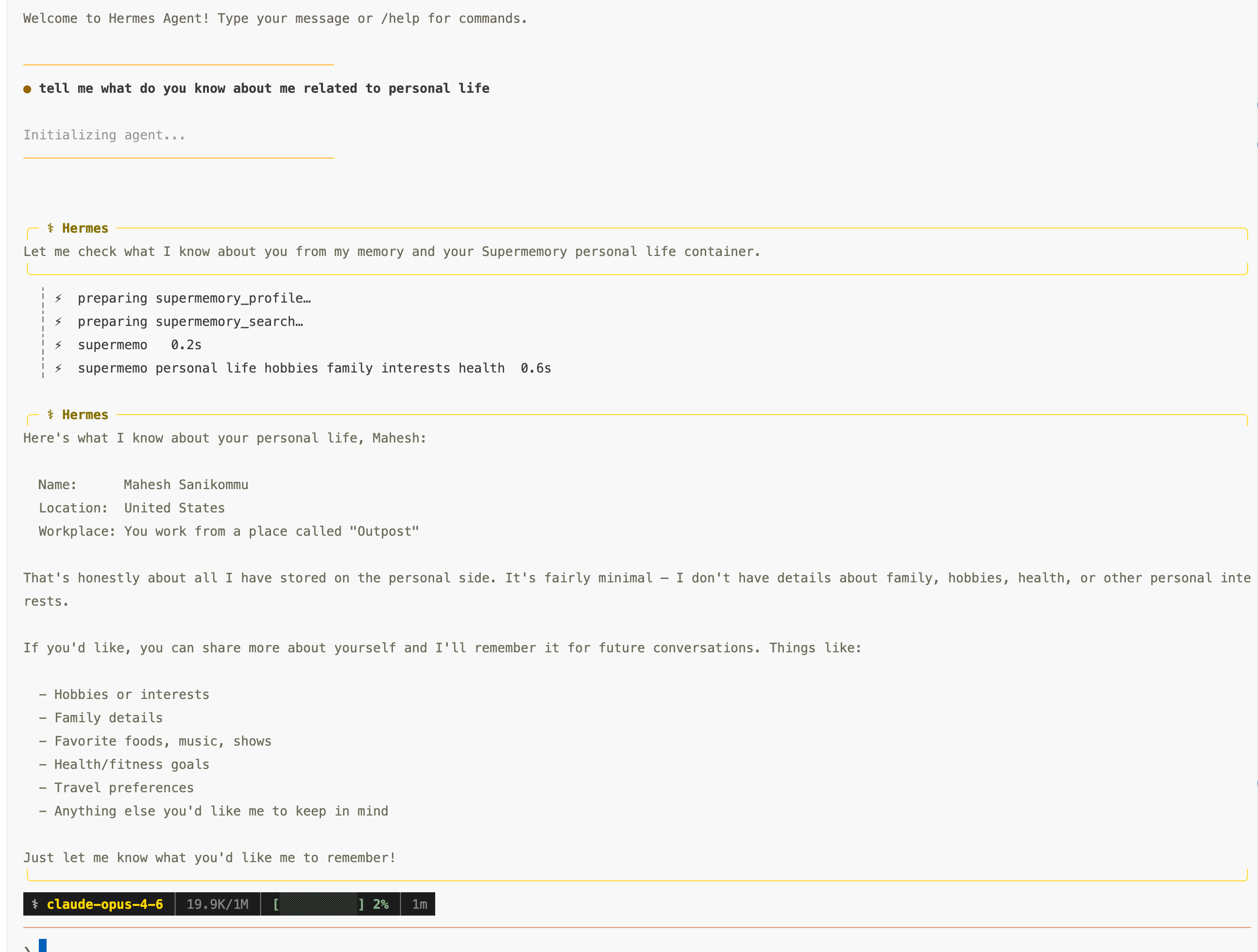
it remembers the conversation, not just the files
So whenever the conversation ends, Supermemory is not going to update files like memory.md or user.md. It actually creates useful information and adds to your user profile so whenever your next session starts, it will automatically load the useful information itself, not just a single large flat file throwing at the agent
it doesn’t throw away the good stuff when context gets squeezed
Long threads hit context compression. The provider hooks before that window is discarded and can push salient user-side content into Supermemory so it survives the trim. If you’ve ever watched important detail evaporate when the summary rolled in, this is the opposite: compress the window, keep the memories.
it plays nice with Hermes’s built-in memory
We’re not replacing MEMORY.md / USER.md. When you add to built-in memory, the provider can mirror those writes into Supermemory in the background—local files stay the source you can edit; the cloud layer stays searchable and profile-aware.
it fails gracefully
If the API misbehaves or the network flakes, a circuit breaker backs off after repeated failures so your agent loop doesn’t thrash. Memory should enhance Hermes, not brick a session.
The technical piece that makes this work is what we call hybrid memory.
A lot of “memory” products are really RAG: chunk documents, retrieve similar text, stuff it in the context. That’s fine for a wiki. Actual memory is messier: “that bug” means the one from Tuesday; preferences change; decisions get revisited. Supermemory is built to extract, update, and retrieve in a way that behaves like memory not like a lazy vector search.
On the wire, Hermes gets concrete tools you can steer: supermemory_profile, supermemory_search (with optional rerank and configurable hybrid vs memories-only search mode), supermemory_remember, supermemory_forget. Prefetch can run ****in the background after a turn so the next turn can open with relevant snippets without you manually running search every time.
It is actually interoperable.
You can use the same memory with your OpenClaw, Claude Code, ChatGPT, and also synchronize it with your Google Drive, Notion, Etc. All your context, in one place, which you can fence and give access to different agents, whenever you need it. No lock-in.
Because we handle the infrastructure for you, the total end to end cost also ends up being cheaper!! While giving you the advantage of owning your very own supermemory.
Install (quick) - free to get started
pip install supermemoryhermes memory setup- choose supermemory
- get API key at https://app.supermemory.ai/?plugins=true and paste in terminal
you should see something like this

PRO TIP:
container tag templates (including {identity}), search mode, prefetch limits, rerank, custom containers, base_url for self-hosted—lives in $HERMES_HOME/supermemory.json or the env vars documented in the plugin README.
Stuck on the API or product? Discord or [email protected].
Useful links:
Supermemory Integration Docs: https://supermemory.ai/docs/integrations/hermes
Hermes Agent: https://github.com/nousresearch/hermes-agent?tab=readme-ov-file