Solving the Precision-Recall Tradeoff: Search Result Aggregation


When you're building memory for AI, search is your foundational layer. The way search generally works is straightforward: the user defines a query, and then sets a limit (top-K) on how many search results they want returned. Usually, this is set to 10 or 20.
Once the request hits the server, a response is returned sorted by semantic similarity. More often than not, this basic semantic match answers the query decently well.
However, there's a catch.
Semantic search fundamentally struggles with precision. Because it's just matching vector proximity, there's often noise in those top results. Just because a document uses similar words doesn't mean it actually has the context to answer the user's question.
The Problem with Re-ranking
To solve this precision issue, the industry introduced re-ranking. What re-ranking does is add a reasoning step—usually through a cross-encoder model or an LLM—to pass over the retrieved data and select what would actually be the best match to the query.
Re-ranking is fantastic for precision. It guarantees that the documents returned are highly relevant. But it suffers from a massive flaw: Recall.
You are still constrained by your search limit. If your limit is set to 3, but answering the user's question completely requires pulling context from 5 different documents, you are stuck. You simply do not have enough "slots" to fit the complete answer into the context window.
And if you're using an LLM anyways, might as well do the entire reasoning and only give the LLM what it needs.
The Supermemory Approach: Aggregation
We built Aggregation to solve exactly this issue.
What aggregation does is look at the same corpus of data, and it respects the exact same result limit. However, instead of one slot equalling one literal document, each result slot is a synthesis of multiple documents condensed into one.
By condensing multiple relevant memories to take up only one search result space, you no longer have to choose between precision and recall. You get both.
Seeing it in Action
Let's look at how this actually works within Supermemory. Imagine a memory space containing a bunch of unstructured data about our team and what we do.
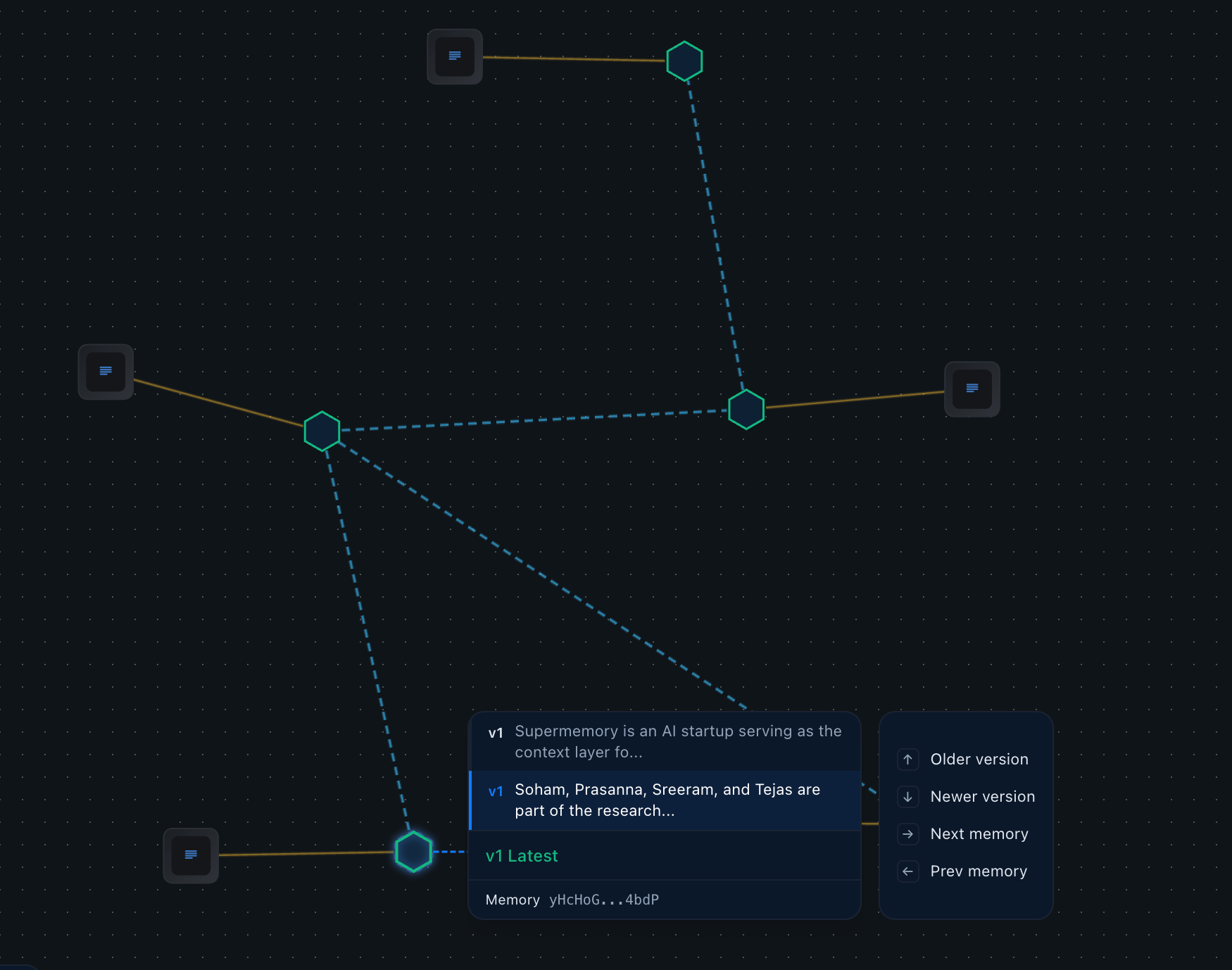
We want to ask a complex, multi-session query: "What is Supermemory and who is behind it?"
To illustrate the point, we'll set our search limit to just 2.
Without Aggregation: When we run this standard search, it returns two memories. These memories might match part of the question fairly well, but there just aren't enough slots to completely answer both parts of the question. The limit of 2 bottlenecks the recall, leaving the LLM with an incomplete picture.
───────────────────────────────────────────────────────────────────────
id: RbqTQjS85K88weNqZbAPzu
memory: Dhravya is the founder and CEO of Supermemory
similarity: 0.77
───────────────────────────────────────────────────────────────────────
───────────────────────────────────────────────────────────────────────
id: yHcHoGPpacSsMYxiKH4bdP
memory: Soham, Prasanna, Sreeram, and Tejas are part of the research team at Supermemory
similarity: 0.75
───────────────────────────────────────────────────────────────────────
With Aggregation: Now, we turn aggregate to true and run the exact same query with the same limit of 2.
It still returns exactly two results—but these results are aggregated from multiple underlying memories.
───────────────────────────────────────────────────────────────────────
id: aggregated_0_1775529845474
memory: Supermemory is an AI startup positioned as the context layer for the agentic era, founded by its CEO, Dhravya.
similarity: 1.00
───────────────────────────────────────────────────────────────────────
───────────────────────────────────────────────────────────────────────
id: aggregated_1_1775529845474
memory: The team behind Supermemory includes members across various functions: the research team consists of Soham, Prasanna, Sreeram, and Tejas; Mahesh serves as an engineer, and Shardul is part of the growth team.
similarity: 0.90
───────────────────────────────────────────────────────────────────────
- Result 1 perfectly synthesizes multiple documents to answer the "What is Supermemory?" part of the query.
- Result 2 aggregates entirely different memories to completely answer the "Who is behind it?" part.
Why this matters for your LLM apps
This feature is incredibly powerful for multi-session use cases. It allows developers to maintain a very small search limit—keeping downstream LLM token usage low, less reasoning effort, and latencies lightning fast—while still achieving the ridiculously high recall and precision required to answer complex questions.
You can simply turn on
aggregate: trueIn the supermemory API to get started.
It's a huge step forward in building a memory engine that actually scales with human complexity.
If you want better memory for your LLMs and apps, you can use this today. Check out our docs, and get an API key on our dashboard.