
LLM Costs Skyrocketing? Real Experts Weigh In


In this blog, we're gonna walk through a fictional story, while learning how to optimize LLMs for cost, and the associated tradeoffs.
Tuesday, 10 June, 2:14 PM PST
The billing alert hit. I was halfway through a product demo, nodding along to myself on Zoom, saying something vaguely confident about “intelligent LLM agents.” On my second monitor, an email notification popped up:
“LLM Spend Exceeded Threshold”
That threshold was already 3x higher than last month.
After the call, I did what any rational and responsible engineer would do: opened the dashboard, stared at the numbers, and refreshed. Twice. Maybe it was a glitch. Just maybe…
Enough denial. With a little bit of digging in, it became clear: our LLM usage per request had exploded. Tokens in. Money out.
So, I got to the task.
I wish I could say I fixed it that afternoon, but I didn’t. Nevertheless, this is the story of how I used 5 different techniques to stop our token bill from killing us, and everything I learned about LLM cost optimization along the way.
Proper Context Management: Only Load What’s Needed
Wednesday, 11 June, 3:30 PM PST
The first person I called was Nikhil, AI Strategy Architect @ Techolution. His company uses LLMs to help enterprise customers modernize legacy code with millions of lines and decades-old COBOL and Fortran.
When we got on a call, he said: “We don’t load what we don’t need.”
“What does that mean?” I asked.
“Well,” he said, “if we’re modernizing a particular function, we don’t send the whole codebase to the LLM. We build dependency graphs. So we only load the components that the function relies on, nothing else.”
That makes sense. Sending everything into an LLM every time bloats the context, slows things down, and burns tokens, increasing the costs.
What Nikhil’s team did instead was smart. Their system allowed them to figure out the parts of the codebase that depended on each other. Then, they chunked and indexed those relevant parts so the LLM would only receive context that mattered to that task.
He explained that this works because large language models don’t “understand” code in the way we do. They pattern-match based on what they’re given. So, if you feed them 3,000 lines of mostly irrelevant code, they’ll waste time (and tokens) trying to make sense of it all.
This approach is backed by plenty of research. In particular, Kabongo et al., 2024 suggest that “A targeted approach to context, where only task-relevant information is provided, is generally more beneficial for model performance than a more comprehensive one.”
That same evening, I looked into our app’s token logs again and realized we were doing the exact opposite. Every time a user asked a question, we were injecting the entire chat history. Didn’t matter if the current question had nothing to do with the previous ten; we were loading it all.
While trying to figure out a solution to this, I accidentally landed on Twitter to ask some questions and learn from others. Obviously, I wasn't scrolling memes tsk tsk.
And then, I found out about Supermemory’s Infinite Chat API. It plugs into your existing LLM stack and allows you to extend your model’s context window infinitely, while simultaneously optimizing long conversations using chunking, smart retrieval, and automatic token management to reduce LLM costs.
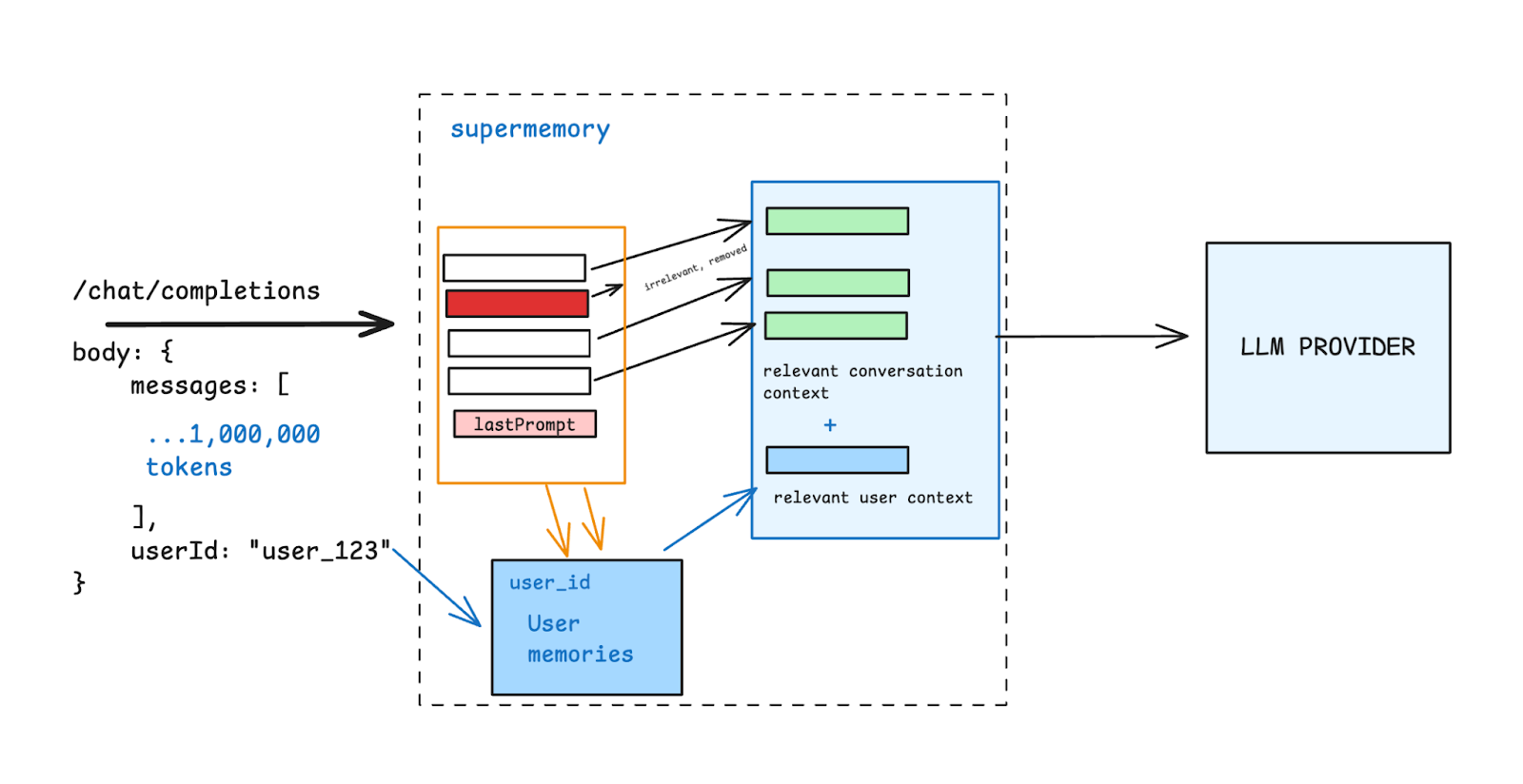
The best part? It took me only 4 minutes and 20 seconds to set up. It has a generous free plan and works with GPT 3.5, GPT-4, 4o, Claude 3 models, and any provider with an OpenAI-compatible endpoint.
Intelligent Prompt Engineering + A/B Testing
Wednesday, 11 June, 4:30 PM PST
An hour later, once I’d stopped injecting 10,000 tokens of unnecessary chat history into every API call, I figured we were safe.
Spoiler alert: we weren’t. The prompts themselves were a mess.
Things like “You are a helpful assistant that…” and “Write in a helpful, friendly tone”, which, okay, are fine once. But we were sending those sentences on every single request. Hundreds of times a day. We were paying LLMs to be reminded of their job. Repeatedly.
That’s when I talked to Nikita Sherbani, CEO at AIScreen. They use LLMs inside a digital signage platform for real-time copy suggestions and templated creative generation. Pretty different product, but the same underlying problem.
“Our biggest cost spike,” he told me, “came from over-relying on high-token completion calls for relatively simple output. What worked? We rewrote prompts to be system-level pre-context instead of repeating instruction per request, cutting token use by ~38%.”
It sounds obvious in hindsight: move static instructions to the system message, and stop sending them over and over again. We did the same. Shifted the tone, structure, and expectations to the system prompt.
Kept user instructions short and scoped. That alone helped trim the fat.
But there was still one lingering question: Which version of the prompt is actually the best?
For that, I called Aryan. He works as an AI engineer at Health GC, building AI voice care agents for elderly patients, which means their LLMs have to be fast, clear, and incredibly reliable. He told me they’d been running A/B tests on prompts for months.
According to him, “Once we started treating the prompt like code by testing variations and reusing shared structures, our costs went down fast.”
Instead of guessing, Aryan’s team actively tests multiple prompt variants in production. They look at everything: output correctness, latency, token usage, and user satisfaction. Often, he calls his LLM using other LLMs and checks the response generated to test it against these thresholds.
Prompt Caching
Thursday, 12 June, 10:00 AM PST
Prompt optimization helped, but we were still spending more than we should. Aryan had mentioned another quick hack we could use.
He explained it simply: most teams forget that their system prompt (the big template that defines behavior and style) doesn’t have to be sent every time.
In their case, Health GC’s AI voice agents for elderly care rely on a long, structured prompt with very small dynamic changes. And in the beginning, they were passing that entire prompt with every single request. Which meant they were basically paying to reintroduce the model to itself over and over again.
A lot of providers actually have built-in ways to avoid this. Gemini and Anthropic, for example, let you cache the system prompt with the model backend itself. Instead of repeating the entire text each time, you:
- Cache the prompt once at the start of the session
- Pass only a reference variable or ID with each request
- Include just the dynamic parts (like a user transcript or updated state)
Aryan told me they switched to this approach and immediately saw costs drop. The tokens used for the static instructions were no longer billed the same way on each call.
Nicolas, Founder @ Introwarm, also implemented prompt caching. His tool analyzes LinkedIn profiles and company data to generate authentic, personalized email openers for sales teams.
“[We] implemented a Redis layer that stores personalization insights for similar profiles/companies. If someone's personalizing emails to multiple people at the same company, we reuse company-specific insights and just vary the personal touches.”
His smart caching had a 23% hit rate, saving him 15% on his monthly LLM costs.
We looked into our setup and realized we were doing exactly what they used to, so we followed their lead.
If your prompts are long templates with only a small variable changing each call, check whether your model provider supports prompt caching. It’s the easiest optimization you’ll ever make.
Structured Outputs
Thursday, 12 June, 11:00 AM PST
Okay, I was done with most of the optimizations on the input side. Now, it was time to look at what the model was spitting out. By default, we were letting it generate free-form text: long paragraphs with different phrasings every time.
However, I realized that structured outputs are the better choice. Instead of asking the model to just “answer,” I asked it to return data in a specific schema:
- A JSON object with known keys
- A numbered list of options
- A simple numeric score
This not only helps with downstream processing, but also cuts down on unnecessary tokens generated on output. A structured JSON is almost always shorter than an essay.
But there are also downsides to this approach that I found. LLMs aren’t deterministic, so sometimes they’ll slip up, especially with larger contexts. They’ll return unexpected formats, which can lead to validation errors. Supermemory also switched some of their tasks from an LLM to purpose-built libraries to counter this in their product.
Well, I was on a spree! All 4 things I tried out worked almost perfectly. I was feeling damn confident, thinking to myself, “I can build literally anything.”
But then came the dark days.
What Not To Do
Thursday, 12 June - Saturday, 14 June
12 June, 8:25 PM PST
I decided to train our own open-source language model to save on per-token costs. On paper, this sounded smart. In practice, it meant provisioning multiple A100 GPUs, tuning datasets, and spending days just getting a stable training loop.
By the time we got the first version running, it barely produced coherent outputs. Instructions were inconsistent, completions were often unrelated to the prompt, and performance was nowhere near GPT-3.5 or Claude 3. The total cost in compute credits and engineering hours ended up far higher than simply using a managed API.
Nikhil echoes this same sentiment. According to him, “We had this genius idea to try out open-source models. Back then, Mistral was huge. Everyone was using Mistral for everything. So we tried creating our own fine-tuned version of Mistral. We put it on GCP, but the hosting and inference costs were ridiculous. Even quantizing didn’t help much. In the end, we had to drop the idea. It was a good learning: if you want to build and deploy your own model, the associated costs are so high that it’s usually better to leave inference to the big guys.”
Friday, 13 June, 11:00 AM PST
Thought maybe I could get clever by quantizing a larger model for deployment on the edge. I read half a blog post about 4-bit quantization and convinced myself this would work.
It did run cheaper. But the drop in output quality was so bad we couldn’t use it for anything customer-facing.
Abhisek Shah, CEO at Testlify, also went through the same thing:
“We initially tried quantizing larger models for deployment on edge, but the drop in output quality made it a no-go. Sometimes cheaper ≠ better.”
One more Friday wasted, uff.
Friday, 14 June, 7:30 PM PST
Still determined to squeeze out more savings, I figured that batching requests was the next obvious win.
I set up serverless endpoints to handle the batch processing. On paper, it looked perfect: elastic scaling, no idle servers, automatic cost optimization.
But, in what can only be called life, it didn’t work out as I thought it would.
Cold starts made latency swing all over the place. Sometimes a request would return in 300 milliseconds. Other times, it sat for ten seconds doing nothing. Because our batches were large, even a short delay meant we burned through overage credits faster than I could track them.
Hidden idle fees made it worse than a dedicated container. After two days of tweaking configurations and trying different scaling policies, I gave up.
Don’t Always Use LLMs
Monday, 17 June, 10:00 AM PST
Well, along the way, I found out that we were using LLMs for things that didn’t really need them. And, we did this, admittedly, because it’s easy and sounds cool.
"AI-powered" is all the buzz today, isn’t it?
But, sometimes, those operations can be done manually, saving a lot of cost and often leading to better outputs as well. Nikhil had said the same thing to me on the call a few days back, “It’s almost ironic that you need more people in the planning stage to save money on AI later. Because if you don’t plan, you’ll end up using LLMs for things a human or a small deterministic script could do.”
When he removed some of his code modernization workflows from his LLM processes and instead did them manually, he saw much lower costs.
You need to take a deep, hard look at your own pipeline and reflect on whether an LLM makes sense or not. That is where the answer lies for most small companies.
Conclusion
Today, 20 June, 11:00 PM PST
Looking back, the learnings are pretty clear. It’s a bunch of small, practical decisions: loading only the context we needed, writing better prompts, batching requests, and sometimes just using simpler tools instead of defaulting to an LLM.
If I had to do it again, I’d start planning for this earlier. As Nikhil put it, it’s almost funny how you need more people thinking ahead to avoid wasting money later.
And if you’re in the same spot, don’t feel like you have to build every piece yourself. Supermemory ended up saving us a lot of time and cost. Their context extender alone reduced our usage by over a third, and it was easy to plug into our stack.
Hope this log helps you avoid some of the trial and error and keep your costs under control as you scale.
Disclaimer: I, the developer, am fake. The log of a developer working at an AI startup is a creative structure we undertook for experimentation and engagement. All the content and experts, and their opinions are real, though.