
2 Approaches For Extending Context Windows in LLMs


Transformer-based large language models have become the poster boys of modern AI, yet they still share one stark limitation: a finite context window. Once that window overflows, performance drops like a rock or the model forgets key details.
This guide walks through two complementary strategies that lift those limits:
- Semantic Compression: Shrink a single, extremely long document so it slips inside an ordinary LLM window without architectural changes
- Infinite Chat with Supermemory: Keep multi-hour conversations coherent by retrieving only the most relevant history at every turn
Along the way, you’ll set up Python environments, run clustering and summarization pipelines, and slot a transparent proxy into any OpenAI-compatible SDK to help your team ship better products faster.
Note: You can find the code in the GitHub repo here.
Why LLMs Struggle With Length
Self-attention, the mechanism that gives transformers their uncanny language skills, scales quadratically with sequence length. In short, every time you double the input, the compute necessary to infer it quadruples. And while current foundational models can stretch their window from 128,000 tokens and up, sooner or later, the window dries up. When it does, you face an unpleasant choice:
- Truncate the context, losing historical context altogether
- Summarize the context, maintaining some history, but potentially losing important details
Even with a rolling summarizer, you're sending a huge amount of tokens back and forth to maintain a mere outline of your historical context.
A smarter answer is to adapt your prompts dynamically so the model sees everything it truly needs and nothing it doesn’t. In this guide, we'll look at a couple of different approaches to this, the first of which is called "Semantic Compression."
Extending Context Part One: Semantic Compression
What if you could drop a full-length, unabridged novel into a model's context window and get useful answers back without any hallucinations? This is exactly the kind of context extension that semantic compression makes possible.
The technique, outlined in this paper, adds a compression layer that squeezes text down to roughly one-sixth its original size.
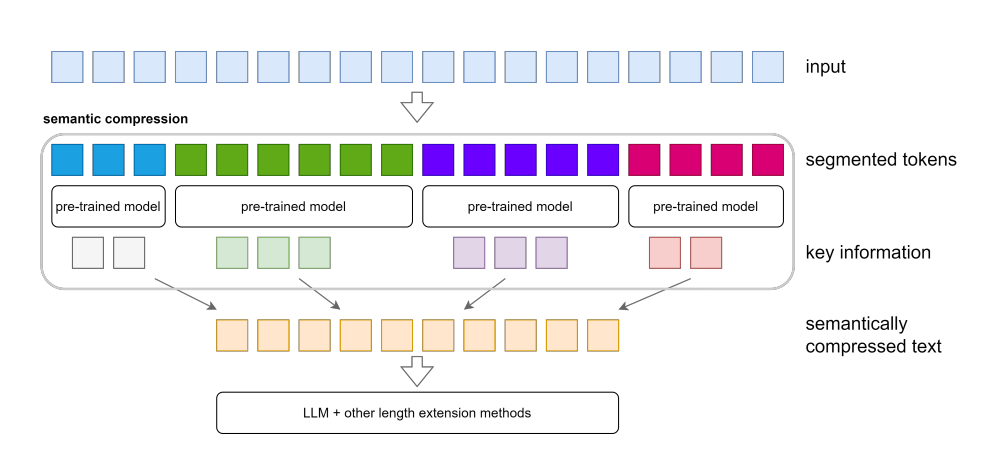
TL;DR: How the algorithm in the paper works:
- Segment the input: Split the document into sentence blocks that fit a summarizer’s 512-token limit.
- Embed and graph: Turn each block into a MiniLM vector and build a similarity graph.
- Spectral clustering: Detect topic boundaries so each cluster covers a coherent theme.
- Run parallel summaries: Run a lightweight BART variant on every cluster concurrently.
- Reassemble the chunks: Glue summaries back together in their original order.
- Feed as context: Send the compressed text plus your question to any LLM.
Here's a more detailed technical breakdown of how it works:
The paper argues that most of natural language is incredibly redundant and wasteful. Multiple sentences often convey overlapping concepts. Entire paragraphs might elaborate on a single key point. The compression method identifies and preserves information-dense segments while removing repetitive portions, in effect, increasing the context window.
Often, real-world textual content has hierarchical structures, where each section explores a particular topic, and all the sections are somewhat mutually independent. These sections resemble cliques in graphs.
A clique is a group of nodes where everyone connects to everyone else. They form dense clusters of connections.
So, the algorithm starts by constructing a similarity graph from the text corpus. Then, several spectral clustering algorithms are implemented to identify the underlying cliques or topic structures.
Traditional clustering algorithms like k-means assume clusters are roughly spherical and similar in size. But real documents don't work that way. You might have a dense technical section followed by a sparse narrative passage. One subtopic might span three paragraphs, while another gets covered in a single dense paragraph.
Spectral clustering analyzes the eigenstructure of the similarity matrix. Basically, it finds the natural ways the graph wants to split apart. It can detect these irregular semantic boundaries that other clustering methods miss.
These chunks of text for each section are then processed in parallel using a pre-trained summarization model on them concurrently. The BART variant is specifically chosen for its ability to create abstractive summaries. It synthesizes new content that captures multiple concepts more efficiently.
The real technical achievement is maintaining semantic fidelity while achieving 6:1 compression ratios. Each summary sentence must encode roughly six times the semantic density of typical prose. This works because BART's denoising autoencoder training taught it to identify and preserve essential information while discarding redundant expressions.
Finally, these summarized chunks are then stitched together and passed to the LLM.
Experiments from the paper show that Llama 2 retains more than 90 percent accuracy on pass-key retrieval tasks, even when the source material balloons past 60,000 tokens. Below, we'll look at what it takes to build your own semantic compression layer to handle outsized prompt sizes.
Setting Up the Environment
Modern context-extension pipelines lean on a handful of mature Python libraries. Install the following:
pip install torch sentencepiece sentence-transformers scikit-learn tqdm
This one-liner pulls in PyTorch for tensor math, Transformers for both the summarizer and the downstream LLM, Sentence-Transformers for MiniLM sentence embeddings, scikit-learn for spectral clustering, and tqdm for friendly progress bars.
Once the packages are in place, you’re ready to ingest raw text.
Loading and Normalizing Text
Documents arrive in a variety of formats like PDFs, scraped HTML, or plain UTF-8 files. Normalizing them up front removes hidden Unicode quirks and errant whitespace that would otherwise derail token counts later.
Create a Python file and write the following code:
from pathlib import Path
import re, unicodedata
def load_text(path: Path) -> str:
raw = path.read_text(encoding="utf-8", errors="ignore")
norm = unicodedata.normalize("NFKC", raw)
return re.sub(r"\s+", " ", norm).strip()
The helper reads the file, applies Unicode NFKC normalization so ligatures and full-width characters collapse into canonical forms, then squeezes every run of whitespace into a single space. The result is a clean, single-string corpus.
With a tidy text string in hand, you can safely start dividing it into manageable blocks.
Breaking the Document into Sentence Blocks
Self-contained sentence blocks become the nodes of a similarity graph. They must be short enough for a summarizer (≈512 tokens) yet long enough to preserve local context.
Add the following code to the file:
import nltk
nltk.download("punkt")
from transformers import AutoTokenizer
tok_sum = AutoTokenizer.from_pretrained("facebook/bart-large-cnn")
def sentence_blocks(text: str, limit=512):
sents = nltk.sent_tokenize(text)
block, blocks, start_idx = [], [], 0
for sent in sents:
tentative = " ".join(block + [sent])
enc = tok_sum.encode(tentative)
if len(enc) > limit and block:
blocks.append((" ".join(block), start_idx))
start_idx += len(block)
block = [sent]
else:
block.append(sent)
if block:
blocks.append((" ".join(block), start_idx))
return blocks # [(text, original_position)]
NLTK tokenizes sentences, while the BART tokenizer checks whether appending another sentence would overflow the 512-token guardrail. Each completed block is stored with its original position so you can later stitch summaries back together in order.
Now that the text is chunked, you can quantify how similar those chunks are to one another.
Building a Similarity Graph
To discover topic boundaries, every block needs a numeric fingerprint. MiniLM embeddings supply that signature; cosine similarity converts it into an adjacency matrix ready for graph algorithms.
import torch
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
encoder = SentenceTransformer("all-MiniLM-L6-v2")
def similarity_graph(block_texts):
with torch.inference_mode():
emb = encoder.encode(
block_texts,
batch_size=64,
convert_to_tensor=True
)
return cosine_similarity(emb.cpu()) # dense numpy array
SentenceTransformer generates 384-dimension vectors, and cosine_similarity fills a dense matrix where each cell reflects semantic closeness between two blocks. This matrix is the substrate for spectral clustering, which is used for topic discovery.
Spectral Clustering to Detect Topics
Spectral clustering partitions the graph so that blocks inside the same cluster talk about the same thing, while blocks across clusters drift apart.
from math import ceil
from sklearn.cluster import SpectralClustering
def cluster_blocks(sim_matrix, block_tokens, target=450):
total = sum(block_tokens)
n_clusters = ceil(total / target)
sc = SpectralClustering(
n_clusters=n_clusters,
affinity="precomputed",
assign_labels="discretize",
random_state=0
)
return sc.fit_predict(sim_matrix) # cluster index per block
The code picks a cluster count by dividing total tokens by a “comfort” window (≈450). SpectralClustering then labels each block, grouping semantically tight neighborhoods together.
Clusters become the units you feed to the summarizer.
Summarizing Clusters in Parallel
With coherent topics identified, you can shrink each one independently. Running multiple summaries concurrently makes the pipeline as fast as the GPU will allow.
from concurrent.futures import ThreadPoolExecutor
from transformers import pipeline
summarizer = pipeline(
"summarization",
model="facebook/bart-large-cnn",
batch_size=4 # CPU or MPS-compatible
)
def compress_cluster(text):
return summarizer(
text,
max_length=256,
min_length=64,
do_sample=False
)[0]["summary_text"]
def summarise_chunks(blocks, labels):
clusters = {}
for (txt, pos), lab in zip(blocks, labels):
clusters.setdefault(lab, []).append((pos, txt))
ordered = [" ".join(t for _, t in sorted(v))
for v in (clusters[k] for k in sorted(clusters))]
with ThreadPoolExecutor(max_workers=4) as pool:
return list(pool.map(compress_cluster, ordered))
A ThreadPoolExecutor fans out four concurrent calls to the BART summarizer. Each cluster collapses into a 64 to 256-token synopsis, slashing the overall length by a factor of six to eight. All summaries come back ordered, ready for reassembly.
Next, we'll merge the compressed snippets into a single prompt.
Reassembling and Prompting the LLM
Putting the pieces together is as simple as concatenation, but with a big payoff: a formerly unwieldy document now fits inside a standard context window.
if __name__ == "__main__":
path = Path("input.txt")
text = load_text(path)
blocks = sentence_blocks(text)
block_texts = [txt for txt, _ in blocks]
block_tokens = [len(tok_sum.encode(t)) for t in block_texts]
sim_matrix = similarity_graph(block_texts)
labels = cluster_blocks(sim_matrix, block_tokens)
compressed_chunks = summarise_chunks(blocks, labels)
compressed_text = "\n\n".join(compressed_chunks)
question = "Summarize the protagonist's character arc."
prompt = f"<s>[SYSTEM]\n{compressed_text}\n[/SYSTEM]\n[USER]\n{question}\n[/USER]\n"
inputs = tok(prompt, return_tensors="pt")
inputs = {k: v.to(DEVICE) for k, v in inputs.items()}
out = model.generate(**inputs, max_new_tokens=512)
print(tok.decode(out[0], skip_special_tokens=True))
The compressed text becomes a system message, the user’s query follows, and the model answers as if it had read the entire original, because semantically, it has.
Also, add this line after the imports:
DEVICE = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
I'm on an M1 Mac, so the code falls back to my CPU since a CUDA GPU isn't available.
The complete code is available in the GitHub repo here.
Extending Context Part Two: Infinite Chat
Semantic compression helps you manage massive inputs that would typically exceed a model's context window. But what if your context grows because users keep interacting? That’s where Supermemory's Infinite Chat comes in.
Long conversations eventually overflow the largest context windows. Like semantic compression, Supermemory's Infinite Chat adds a contextual management layer in front of the model input.
Drop Supermemory's proxy in front of any OpenAI‑compatible API, store and index every interaction, and return only the ones that matter at request time.
How Supermemory's Infinite Chat Works
Infinite chat applies a four‑stage retrieval pipeline every time a new message arrives.
First, it chunks the growing transcript into overlapping blocks. Chunking at sentence boundaries preserves semantics while giving the retriever fine‑grained control over what can be recalled later.
Afterwards, each chunk is embedded and stored in an index, allowing for fast similarity search at inference time.
Finally, when the running prompt nears its token budget, the proxy scores every stored chunk by a blend of relevance (how close the chunk’s embedding sits to the new user prompt) and recency (a timestamp decay.)
The weighting keeps the assistant grounded in the present conversation while still able to reach for older but contextually rich information.
It's worth mentioning that infinite chat enforces a hard budget: it orders chunks by score, retains the top slices that still fit inside the target length, and rebuilds the prompt. Everything else is retained for if and when it becomes relevant again.
The entire operation adds only milliseconds of latency, yet can slash token spend by more than half during marathon chats.
Setting Up Infinite Chat
First, pull in the necessary imports:
import openai
import os
Next, configure your OpenAI client with the Supermemory Infinite Chat proxy:
openai.api_base = "https://api.supermemory.ai/v3/https://api.openai.com/v1"
openai.api_key = os.environ.get("OPENAI_API_KEY") # Your regular OpenAI key
openai.default_headers = {
"x-api-key": os.environ.get("SUPERMEMORY_API_KEY"), # Your supermemory key
}
And finally, create a chat completion with unlimited context:
response = openai.ChatCompletion.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "Your message here"}]
)
Behind the scenes, the proxy stores messages in an embedding index, ranks relevance plus recency, and injects top snippets when the running context would otherwise blow up.
Where to Go from Here
Semantic Compression and Supermemory's Infinite Chat attack the context-limit problem from opposite ends: the former condenses massive static inputs while the latter curates sprawling, dynamic interactions.
Semantic Compression multiplies an LLM’s effective window for single, monolithic documents; Infinite Chat keeps rolling dialogues sharp long after the model's context window would have faded.
Together, they form a practical toolkit for any team that wants to push language models beyond their native inference limits.
Go try Supermemory today. It's free!