
Build Your Own Perplexity in 15 Minutes With Supermemory


Supermemory has a fascinating open-source tool called OpenSearchAI. It's essentially a search assistant similar to Perplexity, but it remembers everything you've searched for and enriches future responses with that memory.
I thought to myself, “This seems cool. But how complicated is it to build something like this?"
So, I challenged myself: Could I recreate a simplified version of this memory-enhanced Perplexity in just 30 mins?
I did, and in this tutorial, I'm going to walk you through exactly how you can do it too. We’ll build our very own mini-clone of OpenSearch using:
- Supermemory's Memory API: A super-simple way to automatically save and retrieve memories without dealing with complicated vector databases or complex integrations.
- Brave Search API: A fast and easy API to pull relevant, real-time web results.
- OpenAI's GPT Model: Just one straightforward call to fuse memories and web search results into clean, easy-to-understand answers.
Honestly, once I saw it working, I couldn’t believe how easy it had been to set up. Let’s dive right in.
Here's the GitHub repo with the full code for you to follow along.
Video
Planning: A Rough Sketch
The actual coding is pretty straightforward for this kind of app, but getting clear on the overall idea and structure helps a ton.
Here's exactly how I thought through this:
How does the original app work?
Supermemory's OpenSearch AI does two main things really well:
- It searches the web and gives clear, concise answers.
- It automatically remembers previous queries, using those memories to give better answers over time.
So, in simple terms, we have two parts: web searching and memory. I wanted my app to do the same.
Picking the Right Tools
Here's my quick thought process on which tools to pick:
Memory: This is the key feature, and luckily, Supermemory already gives me a simple, ready-to-use Memory API. No complicated databases or setup, just a clean, simple SDK to store and retrieve memories.
Web Search: I needed a reliable search API to pull fresh web results. Brave Search is fast, simple, free, and developer-friendly.
Answer Generation: To create those nice, readable responses combining memories and web results, a single call to OpenAI's API is perfect.
Quick UI Sketch
Here's the rough sketch I quickly drew up to clarify my thinking:
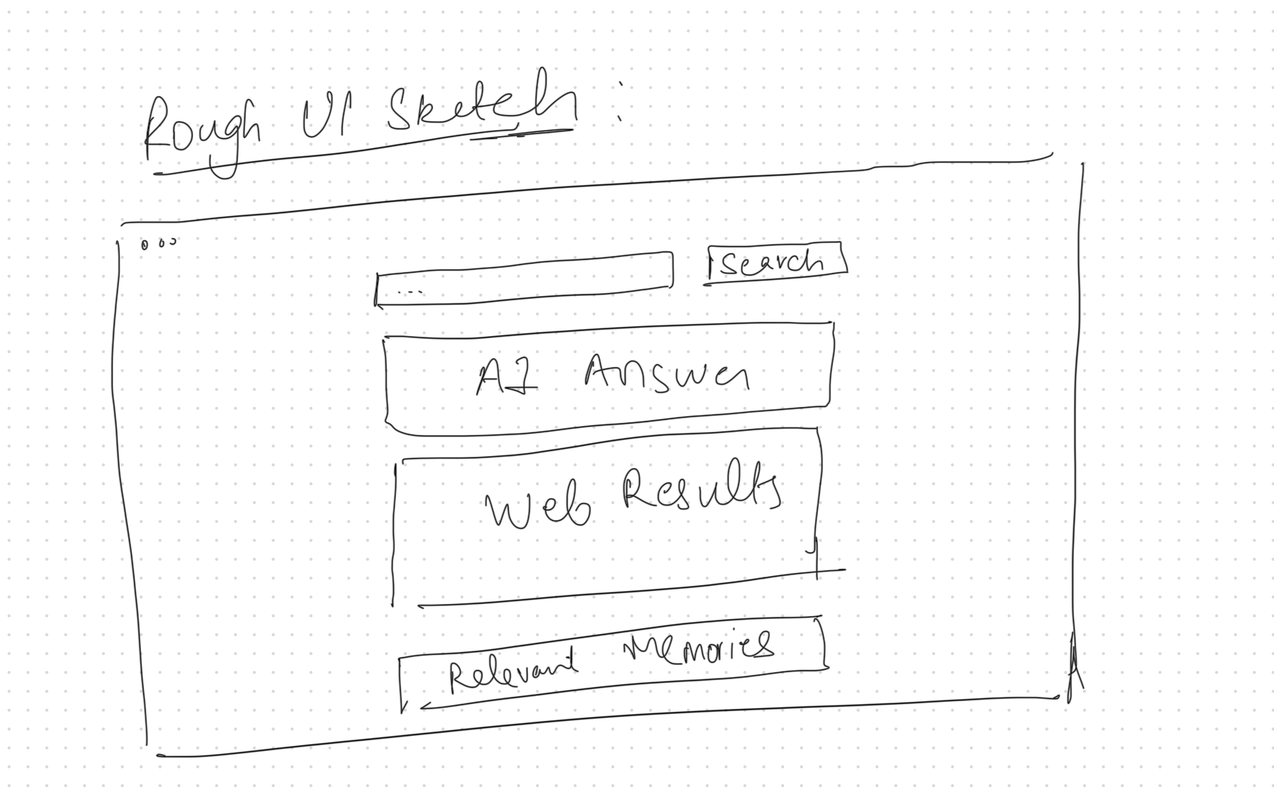
In essence:
- Frontend: Just a simple input for questions and a nice, clean way to show answers, memories, and web results.
- Backend: Takes user questions, interacts with memory, does a quick web search, and uses AI to generate answers.
Here’s what the flowchart looks like:
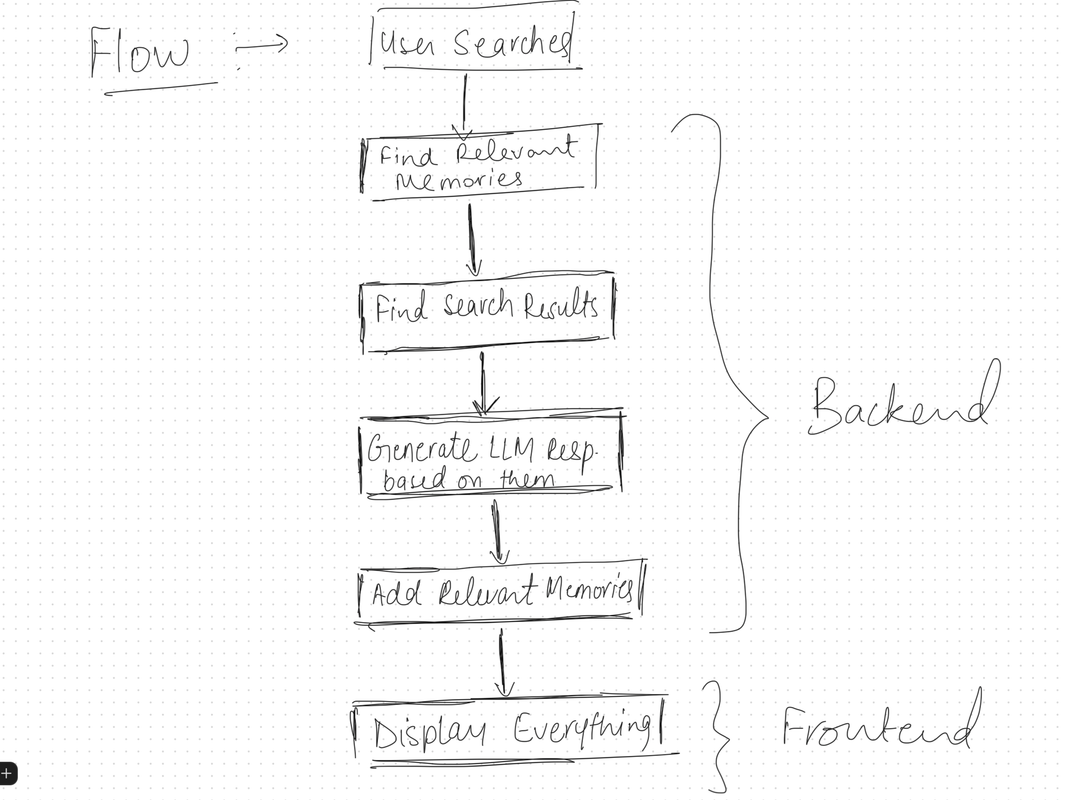
That’s it! Let’s get into the actual coding now.
Building this app: step-by-step
Prerequisites
First, let’s create a folder and install npm. We’ll then install the dependencies.
mkdir mini-opensearch
cd mini-opensearch
npm init -y
npm install express cors dotenv axios supermemory openai
Here’s what the dependencies are for:
- express: Our backend API server.
- cors: Makes sure we don't run into annoying CORS issues.
- dotenv: Simple way to handle API keys and configs.
- axios: Easy HTTP requests.
- supermemory: Easy-to-use memory storage and retrieval.
- openai: For generating AI-powered responses.
Create a free supermemory account and get the API key from your dashboard. Also, go to Brave Search API and register for an account there. They have a free plan we’ll use for this tutorial, but you’ll have to enter your card details.
Finally, generate an OpenAI API Key using these steps.
Then, create a .env file in your folder and enter the following:
SUPERMEMORY_API_KEY=...
OPENAI_API_KEY=...
BRAVE_SEARCH_API_KEY=...
Backend
Awesome, now inside your folder, create a file server.js to set up the Express backend.
Import everything as follows:
// server.js
import express from 'express';
import cors from 'cors';
import dotenv from 'dotenv';
import axios from 'axios';
import supermemory from 'supermemory';
import OpenAI from 'openai';
Configure the dotenv and start Express:
dotenv.config();
const app = express();
// ─── MIDDLEWARE──
// Enable CORS for all routes (you can lock this down to specific origins if you like)
app.use(cors());
// Parse JSON + serve frontend
app.use(express.json());
app.use(express.static('public'));
Create your Supermemory and OpenAI clients as follows:
const memoryClient = new supermemory({
apiKey: process.env.SUPERMEMORY_API_KEY,
});
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
Okay, now, according to our rough flowchart, we need to retrieve relevant memories, conduct web searches, and generate an LLM response.
Let’s start by tackling the web searches part using Brave’s Search API. We’ll create a function that will call the Brave API and get web search results for a query. Based on their documentation, write the following code:
async function braveSearch(query, count = 5) {
const params = new URLSearchParams({
q: query,
count: count.toString(),
country: 'US',
search_lang: 'en',
extra_snippets: 'true',
text_decorations: 'false',
});
const url = `https://api.search.brave.com/res/v1/web/search?${params}`;
const resp = await axios.get(url, {
headers: {
'Accept': 'application/json',
'Accept-Encoding': 'gzip',
'X-Subscription-Token': process.env.BRAVE_SEARCH_API_KEY,
},
timeout: 5000,
});
if (resp.status !== 200) {
throw new Error(`Brave Search error ${resp.status}: ${resp.statusText}`);
}
const results = resp.data.web?.results;
if (!Array.isArray(results)) {
throw new Error(`Unexpected Brave response: ${JSON.stringify(resp.data)}`);
}
return results;
}
The function takes the query as an input parameter and the count variable specifies the number of results to extract. Then, we declare the search parameters using their URLSearchParams object and pass in the query and count.
The extra_snippets feature returns snippets from the webpage relating to our query, which can be useful while passing to the LLM and text_decorations has been set to false to prevent HTML from being given back.
Then, we append these params to the URL and send a GET request with the API Key in the X-Subscription-Token header. Pretty simple!
Now, let’s build the main endpoint of our app that will handle incoming user questions. Here's exactly what our endpoint will do:
- Receive a user question from the frontend.
- Save the user's question into Supermemory for future context.
- Retrieve the 3 most relevant past memories related to this question.
- Fetch fresh web search results from Brave.
- Combine memories and web results in a prompt for OpenAI.
- Generate a crisp, concise answer with OpenAI.
- Save this new AI-generated answer back into memory.
- Send back the generated answer, relevant memories, and web results to the frontend.
Start by creating an Express route:
app.post('/api/query', async (req, res) => {
const { query } = req.body; // User's question
if (!query || typeof query !== 'string') {
return res.status(400).json({ error: 'query must be a non-empty string' });
}
});
Now, using Supermemory’s add function, add the memory to Supermemory:
await memoryClient.memories.add({ content: query });
This will help us remember each question and build better context for future queries. Next, retrieve the top 3 relevant queries from Supermemory:
// Retrieve memories with a limit of 3
const searchRes = await memoryClient.search.execute({ q: query, limit: 3 });
// Get the results from the response
const mems = searchRes.results;
Okay, now if you read Supermemory’s documentation, you’ll realize the response would look something like this:
{
"results": [
{
"documentId": "doc_xyz789",
"chunks": [
{
"content": "Machine learning is a subset of artificial intelligence...",
"isRelevant": true,
"score": 0.85
}
],
"score": 0.95,
"metadata": {
"source": "web",
"category": "technology"
},
"title": "Introduction to Machine Learning"
}
],
"total": 1,
"timing": 123.45
}
I noticed a couple of things:
- Each memory has multiple "chunks" of text, and each chunk has a relevance score.
- Some chunks aren't relevant (isRelevant: false), and we shouldn't include those.
- I only wanted the single most relevant piece of text from each memory to keep things concise and focused for our AI.
So, here’s the logic I went with:
- Step 1: Loop over the top 3 memories Supermemory gave me (already sorted by overall memory score).
- Step 2: For each memory, find only the relevant chunks (isRelevant: true).
- Step 3: Pick the chunk with the highest score (since that's probably the most useful piece).
- Step 4: Create a simple bullet-point list where each bullet combines the memory's title and the best chunk's content.
Here’s how the code looks:
//Take the top 3 memories
const top3 = mems.slice(0, 3);
const memoryContext = top3.map(mem => {
// Filter relevant chunks only
const relevantChunks = mem.chunks.filter(c => c.isRelevant);
// Pick the most relevant chunk (highest score)
const bestChunk = relevantChunks.reduce((best, c) => c.score > best.score ? c : best);
// Format as "Title: content"
return `- ${mem.title}: ${bestChunk.content}`;
}).join('\n');
Great! Now, let’s add a line to do the web search:
const webResults = await braveSearch(query, 5);
Our results from Brave include a description of the page and a list of extraSnippets. We’ll enrich the results with both to make sure our LLM gets as much context as possible. Write the following code:
const enrichedResults = webResults.map((r, i) => {
// Collect all available snippets: description + any extras
const allSnips = [r.description, ...(r.extraSnippets || [])];
// Choose the longest one (assuming more detail = more context)
const bestSnippet = allSnips.reduce((a, b) =>
a.length > b.length ? a : b
, allSnips[0]);
return {
title: r.title,
url: r.url,
snippet: bestSnippet.trim()
};
});
const webSummaries = enrichedResults
.map((r, i) => `${i+1}. ${r.snippet} — ${r.url}`)
.join('\n\n');
This code collects all the snippets we got back in an array and then chooses the longest snippet for each webpage, assuming the longer one would give us more context.
And then, it returns an object with the title, URL, and the best snippet. Finally, we format them in a clean list.
Awesome! Now, we just need to pass all the information we’ve gathered into our LLM. In the server.js file, create the prompts:
const systemPrompt = `
You are a helpful assistant.
Use the user’s past memories plus these fresh web results to craft a concise answer.
Then list the most relevant URLs at the end.
`.trim();
const userPrompt = `
Query: ${query}
Memories:
${memoryContext}
Web Results:
${webSummaries}
Please answer and then list the top links.
`.trim();
The systemPrompt contains the instructions, while the userPrompt contains the query and the context. Finally, we call OpenAI with these prompts:
const chat = await openai.chat.completions.create({
model: 'gpt-4o-mini',
messages: [
{ role: 'system', content: systemPrompt },
{ role: 'user', content: userPrompt },
],
temperature: 0.2,
});
const answer = chat.choices[0].message.content;
And, the last step is saving the answer to memory and returning everything.
// 6) Save AI answer
await memoryClient.memories.add({ content: answer });
// 7) Return everything
res.json({ answer, memories: mems, searchResults: webResults });
Now, start the server on port 3000:
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => console.log(`Listening on http://localhost:${PORT}`));
Voila! The backend is done. This took 20 mins tops. Now, onto the frontend.
Frontend
I’m keeping things simple here. So, I won’t be using any React or Tailwind. Just plain old HTML, CSS, and JS.
Our goal is to let the user enter a query, send it to the backend, and show the answer, web results, and relevant past memories.
Inside your project folder, create a public folder and an index.html file inside it.
Here’s the basic HTML skeleton:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Mini OpenSearch AI</title>
<!-- For rendering Markdown responses and sanitizing -->
<script src="https://cdn.jsdelivr.net/npm/marked/marked.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/purify.min.js"></script>
<style>
body {
font-family: sans-serif;
max-width: 800px;
margin: 2rem auto;
line-height: 1.6;
}
input {
width: 70%;
padding: 0.6rem;
font-size: 1rem;
}
button {
padding: 0.6rem 1rem;
font-size: 1rem;
margin-left: 0.5rem;
cursor: pointer;
}
h2 { margin-top: 2rem; }
#answer { background: #f6f8fa; padding: 1rem; white-space: pre-wrap; }
ul { list-style: none; padding: 0; }
li { margin-bottom: 1rem; }
a { color: #0366d6; text-decoration: none; font-weight: bold; }
a:hover { text-decoration: underline; }
.snippet { color: #444; margin-top: 0.25rem; }
</style>
</head>
<body>
<h1>Mini OpenSearch AI</h1>
<div>
<input id="query" placeholder="Ask something…" />
<button id="search">Search</button>
</div>
<h2>Answer</h2>
<div id="answer">Your AI-enhanced answer will appear here.</div>
<h2>Web Results</h2>
<ul id="results"></ul>
<h2>Relevant Memories</h2>
<ul id="memories"></ul>
This has some basic styling and just four sections: ask something, AI-enhanced answer, web results, and relevant memories.
Here’s what it looks like:
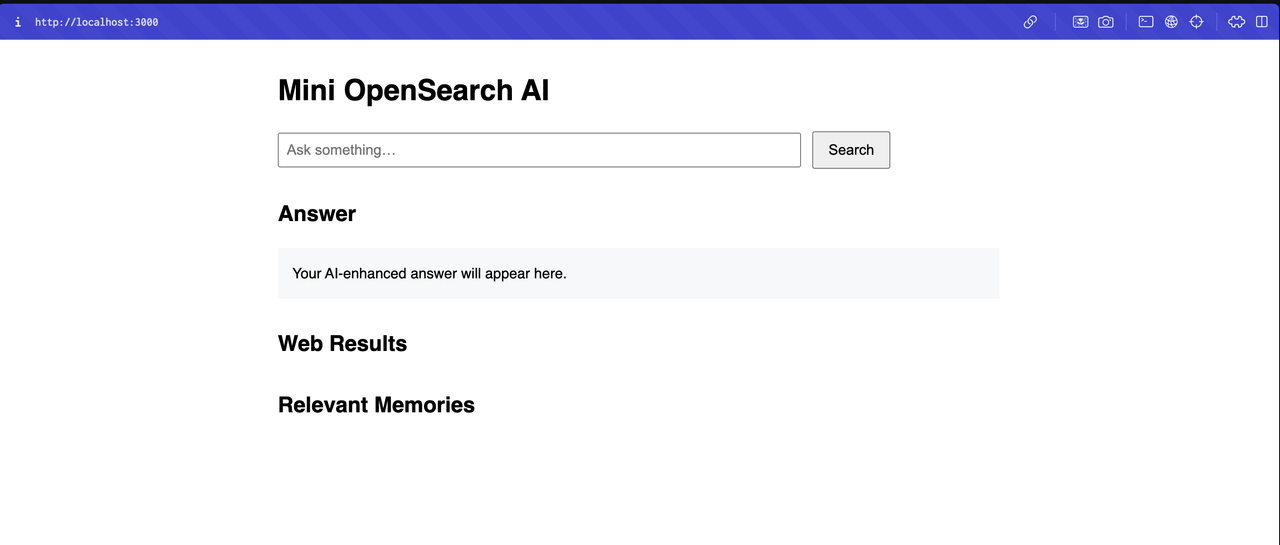
Now, let’s add the logic when the user presses ‘Search’. Here’s how:
<script>
const queryInput = document.getElementById('query');
const searchButton = document.getElementById('search');
const answerDiv = document.getElementById('answer');
const resultsList = document.getElementById('results');
const memoriesList = document.getElementById('memories');
searchButton.addEventListener('click', async () => {
const query = queryInput.value.trim();
if (!query) return alert('Please enter a query.');
// Show loading state
answerDiv.textContent = 'Loading…';
resultsList.innerHTML = '';
memoriesList.innerHTML = '';
try {
const res = await fetch('/api/query', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ query })
});
if (!res.ok) throw new Error(`Server error: ${res.statusText}`);
const { answer, searchResults, memories } = await res.json();
const rawHtml = marked.parse(answer);
answerDiv.innerHTML = DOMPurify.sanitize(rawHtml)
// Render Brave search results
for (const r of searchResults) {
const li = document.createElement('li');
const link = document.createElement('a');
link.href = r.url;
link.target = '_blank';
link.rel = 'noopener';
link.textContent = r.title;
li.appendChild(link);
const snippet = document.createElement('div');
snippet.className = 'snippet';
snippet.textContent = r.description;
li.appendChild(snippet);
resultsList.appendChild(li);
}
const top3 = (memories || [])
.sort((a, b) => b.score - a.score)
.slice(0, 3);
for (const mem of top3) {
// find the most relevant chunk
const chunk = Array.isArray(mem.chunks)
? mem.chunks.reduce((best, c) => c.score > best.score ? c : best, mem.chunks[0])
: { content: '' };
const li = document.createElement('li');
li.className = 'mem-item';
// show title and chunk content
li.innerHTML = `<strong>${mem.title}</strong><br>${chunk.content}`;
memoriesList.appendChild(li);
}
} catch (err) {
console.error(err);
answerDiv.textContent = 'Error: ' + err.message;
}
});
</script>
Most of the above logic is simple. We add an eventListener called ‘click’ to the search button. That means, whenever the button is clicked, we run the given function.
Meanwhile, the function extracts the user’s query from the input box, sends a POST request to our API endpoint, and waits for the response. Then, it converts the Markdown response to normal text and renders the Brave result and the relevant memories.
And, that’s it! You’ve built your very own Perplexity/Supermemory OpenSearch clone. It wasn’t that hard, right?
Now, you can fire away and test this! Start the server using:
node server.js
And then open your browser and go to http://localhost:3000
Conclusion
And that’s a wrap. You now have your own mini clone of OpenSearch AI. The whole point of this wasn’t to build something massive or production-ready. It was to show how surprisingly little it takes to wire something like this up when you’ve got the right tools.
Once you have memory as a primitive, you start thinking differently about what apps can do. You stop worrying about sessions and state and all that, because the app can just remember.
If you’re curious, go try Supermemory. Sign up, play around, plug it into whatever you’re working on. You’ll be surprised how far you can get with a single .add() and .search().
Hope this helped. Go build something fun.