
AI's next big thing: personalization and (super)memory.


You are probably thinking of AI memory in the wrong way.
Over the last few years, we've all seen a lot of absolutely world-changing trends in AI. Things that totally changed the way we interact with computers today. The first one was data (models start getting smarter), then it was inference (everyone is able to run them), and vector databases/RAG. Now there are agents everywhere (with claude code). So,,, what's next?I believe that the next big inflection point is memory. And by memory, I mean truly magical personalization. A feeling that the user gets, when their assistant will proactively bring up things that they would never have expected. When context lengths are no longer a concern, and people can just have long running, thoughtful conversations with their assistant.I believe that this true personalization can be brought in some beautifully simple ways. But first, let's talk about what the industry is getting wrong.
Vector databases/ RAG is NOT memory.
RAG is just taking some raw info, embedding it, and making it searchable.
The top match comes back, and LLM uses it to answer a question.
It's a single step. It's stateless, unversioned, doesn't "evolve" with the user. Doesn't preserve temporality (understanding of time).
Memory evolves, updates, and derives/learns new information.
Let's take a scenario.
Day 1: "I love Adidas sneakers"
Day 30: "My Adidas broke after a month, terrible quality"
Day 31: "I'm switching to Puma"
Day 45: "What sneakers should I buy?"RAG will give the wrong results.
# RAG sees these as isolated embeddings
query = "What sneakers should I buy?"
# Semantic search finds closest match
result = vector_search(query)
# Returns: "I love Adidas sneakers" (highest similarity)
# Agent recommends Adidas 🤦Memory fixes this.
# Supermemory understands temporal context
query = "What sneakers should I buy?"
# Memory retrieval considers:
# 1. Temporal validity (Adidas preference is outdated)
# 2. Causal relationships (broke → disappointment → switch)
# 3. Current state (now prefers Puma)
# Agent correctly recommends Puma ✅Apart from this, RAG doesn't 'forget' irrelevant information. If i had an exam when I was in 10th grade that I was really scared about, that is no longer even relevant to my day-to-day life. Why would I want the AI to remember that?The real way to do this well would be to get the "best of all worlds" - that is, hybrid search. we have a great documentation page that explains this in much higher detail.
Agentic discovery / Filesystem search is stupid way of doing memory
A knee-jerk reaction to this would be "Oh, let the agent look through all the information and let it find out what to do!"
This will work. But is this what the world expects? Agentic discovery would take an agent atleast 10 seconds - let's say, even 1 full second to look through all the info it needs. Unfortunately, this is too slow with most of the real world use cases.
That's too slow, because memory is in the hot path of an 'agent lifetime'. This is even before the agent even starts saying anything useful. Users don't want their agents slow. they want them fast.
AT BEST memory should take about 200-400 MILLISECONDS.
The added cost here is that this would be expensive to do at scale. Memory is something you want to reference on every single conversation turn. Running an agentic search would almost certainly be unaffordable, eventually.
This remains a concern with context dumping, because you are
1. paying a lot for little work done, and
2. almost always hallucinating the model.
3. The time to first byte is still, really slow.
And what about compaction, you ask?
Compaction is great for coding agents because all the information is in a structured, single session that you are compacting. You cannot really personalize just with compaction, because personalization is all about the little details.
The beautifully simple architecture - supermemory.
So, memory is important. It should be fast. it should scale, and not be expensive. We understand the constraints now.But how do we build it? At supermemory, we have been thinking a lot about the best way to approach this memory problem, and build it like the human brain. https://supermemory.ai/blog/memory-engine/
- A vector-graph architecture to track knowledge change.
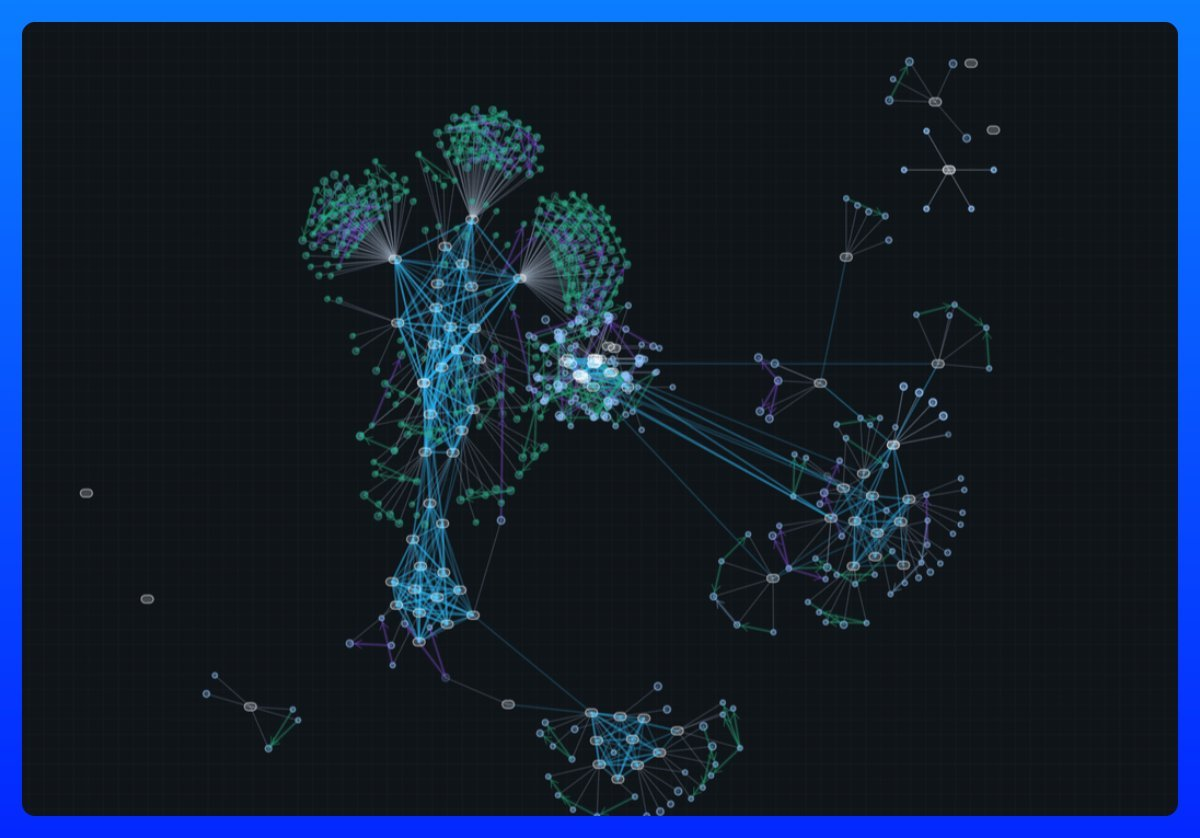
We don't approach graphs the "traditional" way - No (entity, relation, entity) triplets, no long traversal times. The supermemory graph is a simple way to track how facts and knowledge about a single entity changes, over time.It automatically updates, derives, and extends on top of the information it has. It's all facts, since there's only one "real" entity - the main user we are trying to understand.
Updates: Information Changes
Memory 1: "Alex works at Google as a software engineer"
Memory 2: "Alex just started at Stripe as a PM"
↓
Memory 2 UPDATES Memory 1Derives: Sleep-time compute for an agent
Memory 1: "Alex is a PM at Stripe"
Memory 2: "Alex frequently discusses payment APIs and fraud detection"
↓
Derived: "Alex likely works on Stripe's core payments product"This, paired with automatic forgetting, makes this approach a really, really good primitive for AI systems.

2. Memory is not only retrieval!!! The magic of User Profiles
Traditionally, memory systems have relied on retrieving relevant information BEFORE responding.However, this doesn't really work for "non-literal" questions. Many times, the user would say something really generic, like a "Hello!", or ask about something that not implicitly mentioned, ever, but the agent knows just enough to answer the question.
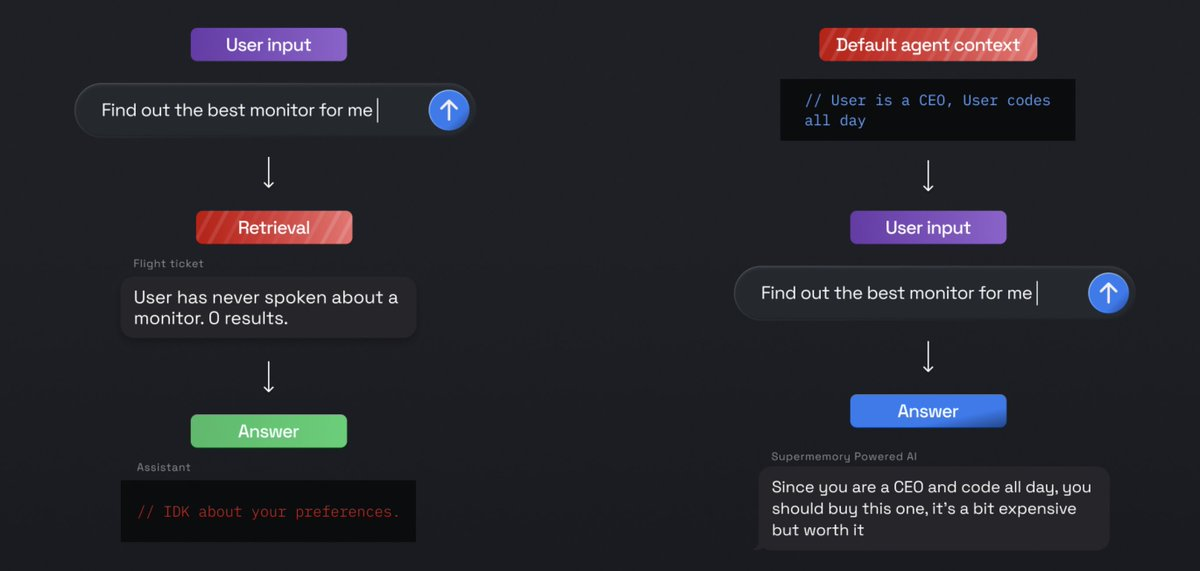
So, even saying a "Hello! I am really sad" should bring up "Hey, how's it going with that new customer now?". Not some generic-ahh response.
We built something called user profiles, which gives the agent a "default context" it should ALWAYS know about a user.
Think of it as a RAM layer, with both "static" (things the agent should know by DEFAULT) - like the name of the user, their age, etc, and "dynamic" - the episodic / currently-ongoing-endeavours of the user.
STATIC CONTEXT (always true unless explicitly updated)
- Name: Dhravya
- Location: San Francisco
- Role: Founder & CEO of Supermemory (AI memory + context platform)
- Age range: 18–25
- Interests: AI infrastructure, developer tools, vector search, PostgreSQL
DYNAMIC CONTEXT (things Dhravya has been talking about recently)
- Currently working on: a "Customer Context Graph" for consolidating customer data.
- Actively optimizing: inference cost for Claude and other LLMs.
- Exploring: migrating speech-to-speech from OpenAI to Gemini Live.
- Recent preference change: Adidas sneakers broke → switched preference to Puma.
- Mood: occasionally stressed about infra costs and scale.
This brings out a new way of personalization. Pair this with a retrieval step, and you always have a really personal assistant.
3. Getting the best of both worlds: Hybrid retrieval
Just retrieval is great, and getting the right 'density' of memories extracted will never really happen. So, we also give LLM chunks, if there's no memories associated with them but still may be relevant.
Memories are always fresh, so they are given a higher priority. But to get just the right detail in the memory generation is crucial for us, hence, we only extract what's absolutely needed, and return the chunks anyways on query time.
Paired with user profiles, this makes sure that the agent has all the context it needs (without giving too much!!!!) to answer a question.
sometimes you need memory. sometimes you need RAG.
— Dhravya Shah (@DhravyaShah) December 26, 2025
Most of the times, you need both.
Today, we are launching our hybrid search mode. a new way to bring context to your LLM.
We have found this to improve LLM context by 10-15%. pic.twitter.com/oC0t9VQduQ
Putting it together: Supermemory.
So, that's it. That's how I think LLMs can get the perfect memory that they deserve.
A way to create beautiful user experiences, and make your agents feel unforgettable.
We are building this memory engine at supermemory.ai - and would love for you to try it out, and add it to your own agent!
It's not just about retrieval. It's about true personalization. And it's coming to every single AI agent out there.
It's the next inflection point of AI.